不能抱有半吊子的心态,必须要有坚强的意志和信念。——《甘城光辉游乐园》
线段树
线段树(Segment Tree),一种用于维护区间信息的数据结构。与树状数组相比,它可以实现 的区间修改,还可以同时资瓷多种操作,更具有通用性。
线段树的概念
线段树是一棵平衡二叉树,母结点表示整个区间的和,越往下区间越小。线段树的每个结点对应一条线段(区间),但并不保证所有线段(区间)都是线段树的节点。

线段树的入门食用
每个 结点的子节点是 和 ,假如结点 储存 的和,设 ,那么两个子节点管理的区间就是 和 的和。
考虑使用递归在数组建树。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void build (int l = 1, int r = n, int p = 1)
{
if (l == r)
tree[p] = a[l];
else
{
int mid = (l + r) >> 1;
build (l , mid, p << 1);
build (mid + 1, r, p << 1 | 1);
tree[p] = tree[p << 1] + tree[p << 1 + 1];
}
return ;
}
|
看上去线段树确实比树状数组码量大(详情请见我的另一篇博文《树状数组的养成方法》)
区间修改
在提到区间修改之前,我们要引入一个“懒惰标记”的概念。
懒惰标记
懒惰标记对于那些正好的线段树节点的区间,我们不再递归下去,而是给打上一个“懒惰标记”,等到将来要用到它的子区间时,再向下传递。
先来上一份区间修改的菜(有非常非常详细的解释)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| void update (int cl, int cr, int p, int l, int r, int d)
{
if (cr < l || cl > r)
return ;
else if (cl >= l && cr <= r)
{
tree[p] += (cr - cl + 1) * d;
if (cr > cl)
lazy[p] += d;
}
else
{
int mid = (l + r) >> 1;
lazy[p << 1] += lazy[p];
lazy[p << 1 | 1] += lazy[p];
tree[p << 1] += (mid - cl + 1) * lazy[p];
tree[p << 1 | 1] += (cr - mid) * lazy[p];
lazy[p] = 0;
update (cl, mid, p << 1, l, r, d);
update (mid + 1, cr, p << 1 | 1, l, r, d);
tree[p] = tree[p << 1] + tree[p << 1 | 1];
}
}
|
过程模拟
这个过程的模拟(自己可以先来一遍试试):
1、与目标区间无交集

此时直接剪枝,退出递归。
1
2
| if (cr < l || cl > r)
return ;
|
2、被目标区间包含

此时给 区间赋值,如果不是子节点就打上懒惰标记。
1
2
3
4
5
| tree[p] += (cr - cl + 1) * d;
if (cr > cl)
lazy[p] += d;
|
3、与目标区间有交集但不被包含,此时采用分治思想

此时二分查找区间,向两个子节点传递懒惰标记,修改对应区间,二分标准递归,得到父节点的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| if (cr > l && cl < r)
{
int mid = (l + r) >> 1;
lazy[p << 1] += lazy[p];
lazy[p << 1 | 1] += lazy[p];
tree[p << 1] += (mid - cl + 1) * lazy[p];
tree[p << 1 | 1] += (cr - mid) * lazy[p];
lazy[p] = 0;
update (cl, mid, p << 1, l, r, d);
update (mid + 1, cr, p << 1 | 1, l, r, d);
tree[p] = tree[p << 1] + tree[p << 1 | 1];
}
|
感觉这里的代码也是板子(擦汗)。
另外一提,我们通常把传递懒惰标记值的过程封装成一个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
| inline void push_down (int p, int len)
{
lazy[p << 1] += lazy[p];
lazy[p << 1 | 1] += lazy[p];
tree[p << 1] += lazy[p] * (len - len >> 1);
tree[p << 1 | 1] += lazy[p] * (len >> 1);
lazy[p] = 0;
}
|
然后在 函数里这么调用:
1
| push_down (p, cr - cl + 1);
|
乘法的情况
规定乘法优先,然后我们记两种懒惰标记,乘法和加法,先给这个节点乘上乘法懒惰标记,再加上给到的加法懒惰标记(如还是看不懂,可以去线段树模板题解那边再加深理解)。
还有,不要忘记给父节点的乘法懒惰标记初始化为 ,加法懒惰标记初始化为 , 不然你的成绩就会变成加法懒惰标记的值(威胁)。
1
2
3
4
| tree[p << 1] += (tree[p << 1] * multag[p] + addtag[p] * (len1));
tree[p << 1 | 1] += (tree[p << 1 | 1] * multag[p] + addtag[p] * (len2));
|
单点修改
单点修改便是使左端点等于右端点的时候停就可以了,然后向上合并值,话说如果只有单点修改和区间修改的话,为什么不用树状数组呢?
区间查询
既然已经有了区间修改的经验,直接上区间查询的板子了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| inline int query (int cl, int cr, int p, int l, int r)
{
if (cr < l || cl > r)
return ;
else if (cl >= l && cr <= r)
return tree[p];
else
{
int mid = (cl + cr) >> 1;
push_down (p, cr - cl + 1);
return query (cl, mid, p << 1, l, r) + query (mid + 1, cr, p << 1 | 1, l, r);
}
}
|
一样的二分,一样的传递,一样的合并信息。
线段树的进阶食用
动态开点
通常来说,一般线段树的空间是总区间长的 的常数倍,空间复杂度是 。当我们不需要用到所有子节点的时候,就可以使用到动态开点——不再一次性建好树,而是一边修改,一边查询一边建立。而相应的,不再使用 和 表示左右儿子,而是用两个数组 和 来记录左右儿子的编号。设总查询次数为 ,这样的时间复杂度是 。
比起普通线段树,动态开点线段树有一个优势,就是可以处理零或负数位置。此时求 不能用 ,而是 ,因为 时会退出递归。
因为缓存命中( )等原因,动态开点线段树写成结构体形式往往会快一点。
结构体
这个结构体里存入节点值,懒惰标记,左右儿子的编号:
1
2
3
4
| struct Segment_Tree {
int val, lazy = 0;
int ls, rs;
} tree[MAXN];
|
传递函数
传递与普通线段树只有一点点区别,就是左右儿子记录的更改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| inline void push_down (int p, int len)
{
if (!tree[p].ls)
tree[p].ls = ++ cnt;
if (!tree[p].rs)
tree[p].rs = ++ cnt;
if (tree[p].tag)
{
upd (tree[p].ls, tree[p].lazy, len / 2);
upd (tree[p].rs, tree[p].lazy, len - len / 2);
tree[p].lazy = 0;
}
}
|
这里的区间长度 和 是为了减少误差,可能出现奇数区间长度。
区间修改
区间修改和前面的普通线段树应该没什么区别:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| inline void upd (int p, int d, int len)
{
tree[p].val += d * len;
tree[p].tag = d;
}
inline void update (int l, int r, int d, int p = 1, int cl = L, int cr = R)
{
if (cl >= l && cr <= r)
return upd (p, d, cr - cl + 1);
push_down (p, cr - cl + 1);
int mid = (cl + cr - 1) / 2;
if (mid >= l)
update (l, r, d, tree[p].ls, cl, mid);
if (mid < r)
update (l, r, d, tree[p].rs, mid + 1, cr);
tree[p].val = tree[tree[p].ls].val + tree[tree[p].rs].val;
return ;
}
|
来看一下这段代码:
1
2
3
4
| if (mid >= l)
update (l, r, d, tree[p].ls, cl, mid);
if (mid < r)
update (l, r, d, tree[p].rs, mid + 1, cr);
|
如果不理解,可以模拟一下分区间的过程:
当前查找区间的中点大于目标区间左端点
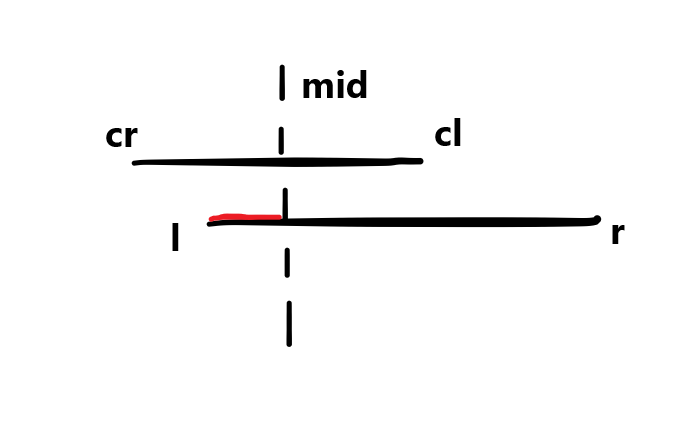
1
2
| if (mid >= l)
update (l, r, d, tree[p].ls, cl, mid);
|
当前查找区间的中点小于目标区间右端点
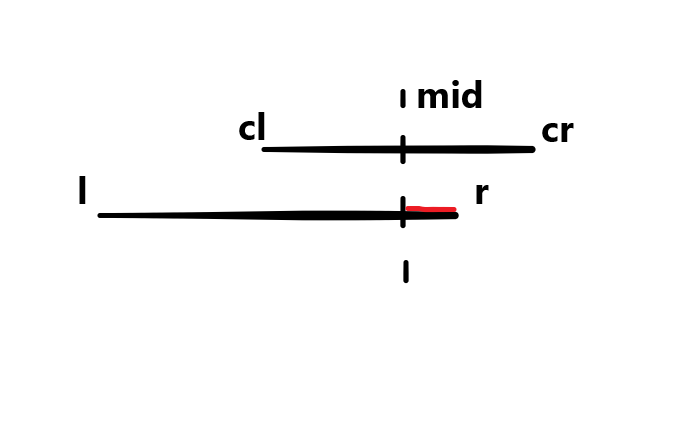
1
2
| if (mid < r)
update (l, r, d, tree[p].rs, mid + 1, cr);
|
如果要问为什么一个是小于号,一个是大于等于号的话,应该是因为左区间往往较长。
查询函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| inline int query (int l, int r, int p = 1, int cl = L, int cr = R)
{
if (cl >= l && cr <= r)
return tree[p].val;
push_down (p, cr - cl + 1);
int mid = (cl + cr - 1) / 2;
if (mid >= r)
return query (l, r, tree[p].ls, cl, mid);
if (mid < l)
return query (l, r, tree[p].rs, mid + 1, cr);
else
return query (l, r, tree[p].ls, cl, mid) + query (l, r, tree[p].rs, mid + 1, cr);
}
|
再来看一下区间判断:
1
2
3
4
5
6
| if (mid >= r)
return query (l, r, tree[p].ls, cl, mid);
if (mid < l)
return query (l, r, tree[p].rs, mid + 1, cr);
else
return query (l, r, tree[p].ls, cl, mid) + query (l, r, tree[p].rs, mid + 1, cr);
|
当前查找区间中点大于目标区间右端点
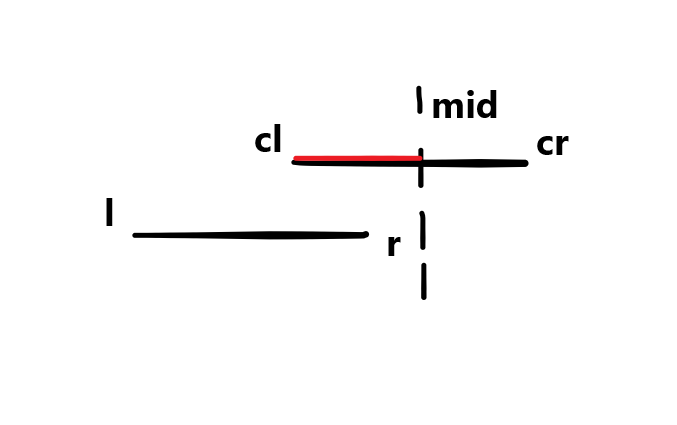
1
2
| if (mid >= r)
return query (l, r, tree[p].ls, cl, mid);
|
当前查找区间中点小于目标区间左端点
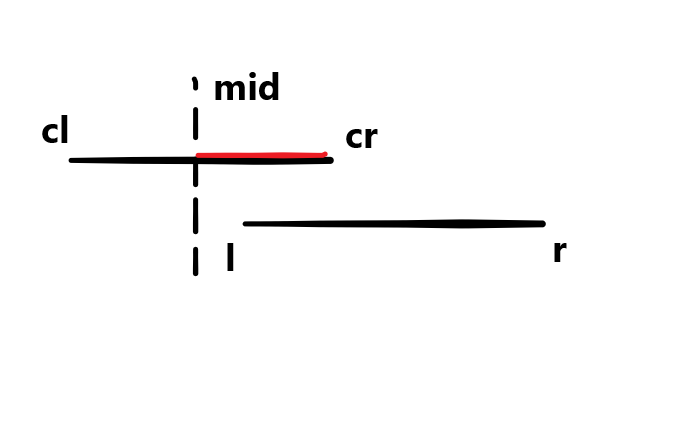
1
2
| if (mid < l)
return query (l, r, tree[p].rs, mid + 1, cr);
|
当前查找区间的左边和右边都被包含
1
2
| else
return query (l, r, tree[p].ls, cl, mid) + query (l, r, tree[p].rs, mid + 1, cr);
|
可以看到,除了在 传递函数里进行了新节点的创建,其他基本与普通线段一致。动态开点线段树不需要 ,通常用在没有给初始数据的场合(比如初始全 ),这时更能表现出优势。
当然,除了动态开点,先离散化再建树也可以达到效果。但动态开点写出来更简单直观,而且在强制在线时只能这样做。
权值线段树
桶我们经常使用。而权值线段树就是用线段树维护一个桶,每个叶节点的权值存的是代表的值出现的次数。它可以 ( 是值域)地查询某个范围内数出现的总次数。不仅如此,它还可以 地求得第 大的数。事实上,它常常可以代替平衡树使用。
由于权值线段树需要按值域开空间,所以常常使用到动态开点。
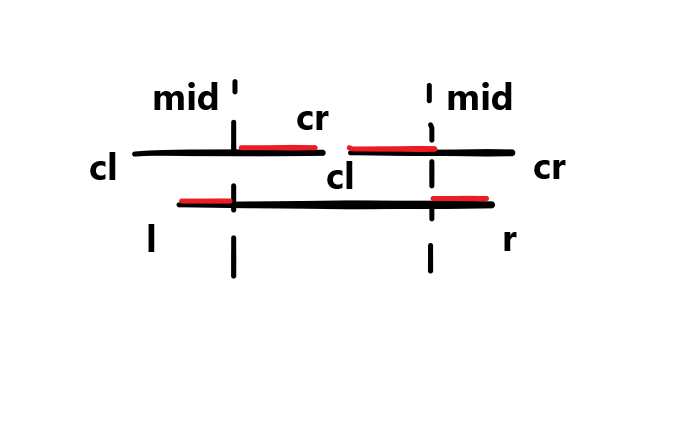
对于这个数组:
我们可以画出这样一张图:
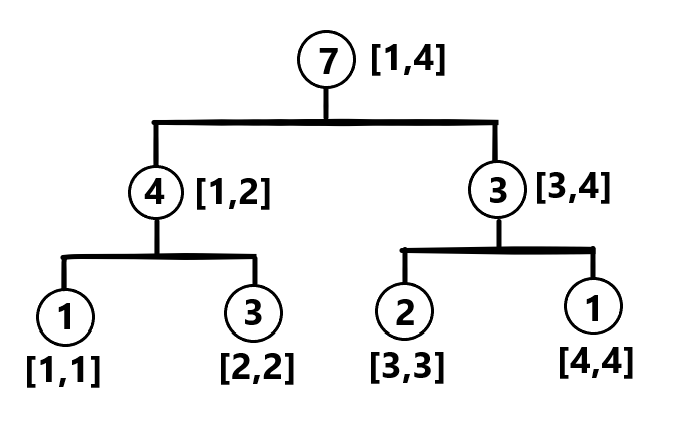
单点修改
单点修改基本与普通线段树一致:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| inline void upd (int p, int d, int len)
{
tree[p].val += d * len;
}
inline void update (int x, int d, int p = 1, int cl = L, int cr = R)
{
if (cl == cr)
return upd (p, d, 1);
push_down (p);
int mid = (cl + cr - 1) >> 1;
if (x <= mid)
update (x, d, tree[p].ls, cl, mid);
else
update (x, d, tree[p].rs, mid + 1, cr);
tree[p].val = tree[tree[p].ls].val + tree[tree[p].rs].val;
}
|
然后在增加或减少一个数字的次数时,这样调用函数:
1
2
3
4
5
6
7
8
| inline void insert (int x)
{
update (x, 1);
}
inline void remove (int x)
{
update (x, -1);
}
|
传递函数
权值线段树只会用到单点修改,所以减少了往下丢懒惰标记的操作:
1
2
3
4
5
6
7
| inline void push_down (int p)
{
if (!tree[p].ls)
tree[p].ls = ++ cnt;
if (!tree[p].rs)
tree[p].rs = ++ cnt;
}
|
查询第 k 大数字
当左子树内权值大于等于剩余查询次数(可以看成是查掉了多少个元素)时,则递归进入左子树进行查询,否则递归进入右子树进行查询,并减去左子树权值:
1
2
3
4
5
6
7
8
9
10
11
| inline int query_kth (int k, int p = 1, int cl = L, int cr = R)
{
if (cl == cr)
return cl;
int mid = (cl + cr - 1) >> 1;
if (tree[tree[p].ls].val >= k)
return query_kth (k, tree[p].ls, cl, mid);
else
return query_kth (k - tree[tree[p].rs].val, mid + 1, cr);
}
|
利用二分思想,当左子树权值大于当前剩余查询次数时,就说明当前要找的数在左区间;当左子树权值小于当前查询次数时,说明前面的个数还不够,要去右边查找,我们可以来模拟一下。
使用上面的图,假设我们现在要找到第 大的数。
第一步,我们先看左子树和右子树的权值,显然选择向右走:
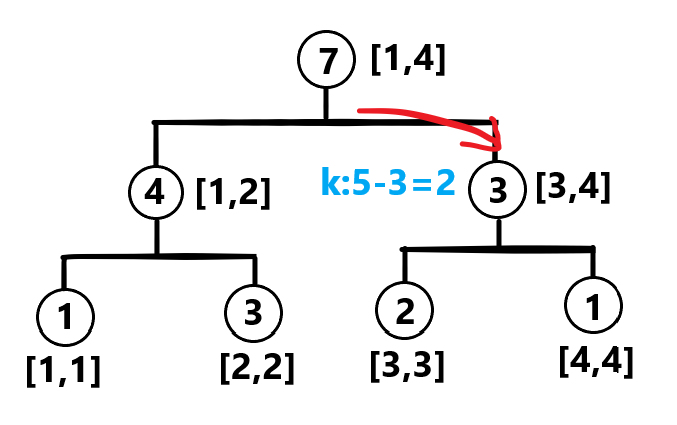
此时查询次数剩下 次,下一次操作我们选择左子树,这里的数据太水了,直接找到了:
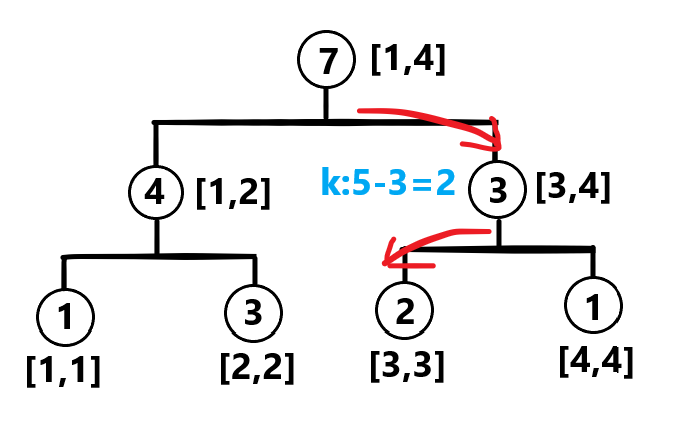
操作原理就是这个每次比较每个小区间内元素的个数,选择左边或右边,至于为什么选择左区间时不用减去查询次数(区间内元素个数),是因为每次进入一个父区间时,我们把左区间看做父区间前 个数,如果 都不到这个数,就不用减去(减去都成负数了)。
查询 x 的排名
只需要查询线段树 权值的区间和再加一就彳亍了,换句话说,就是查在 在前有多少个元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| inline int query (int l, int r, int p, int cl, int cr)
{
if (cl >= l && cr <= r)
return tree[p].val;
push_down (p);
int mid = (cl + cr - 1) >> 1;
if (mid >= r)
return query (l, r, tree[p].ls, cl, mid);
if (mid < l)
return query (l, r, tree[p].rs, mid + 1, cr);
else
return query (l, r, tree[p].ls, cl, mid) + query (l, r, tree[p].rs, mid + 1, cr);
}
int countl (int x)
{
return query (L, x - 1, 1, L, R);
}
int rank (int x)
{
return countl (x) + 1;
}
|
查询前驱
意思就是求 前面那个数。
1
2
3
4
5
| inline int pre (int x)
{
int r = countl (x);
return query_kth (r);
}
|
查询后继
意思就是求 后面的那个数
1
2
3
4
5
6
7
8
9
10
| inline int countg (int x)
{
return query (x + 1, R);
}
inline int suc (int x)
{
int r = tree[1].val - countg (x) + 1;
return query_kth (r);
}
|
线段树的高级食用
线段树合并
现在假设我们有两棵被边缘偷吃过的权值线段树:
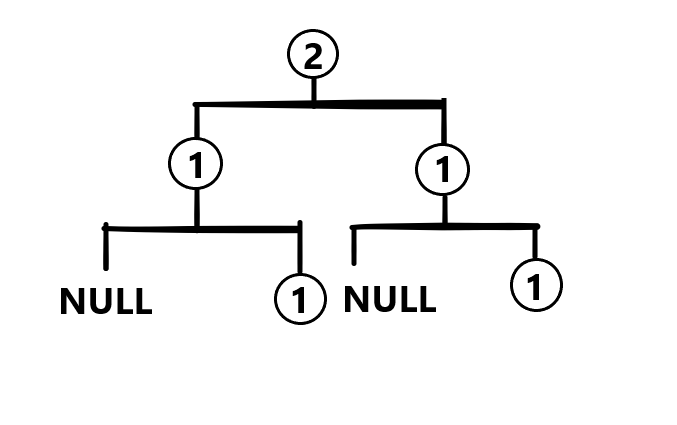
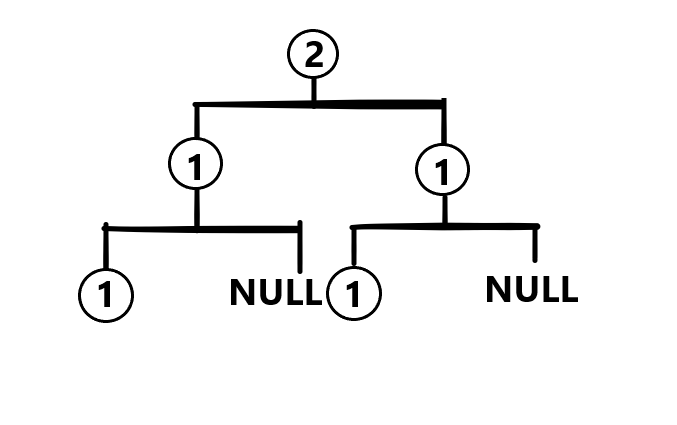
现在我们想要将这两棵线段树合并,最终结果会是这样的:
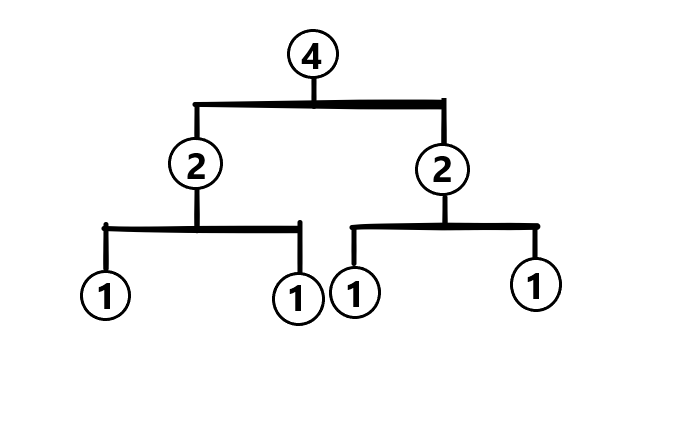
画的好丑(捂脸)。
说回正题,可以看出线段树合并,就是建立一棵新的线段树而且还保存了原有的两棵线段树的信息。最坏的时间复杂度是 。
过程很简单明了,如果第一棵树有一个 位置,但是第二棵树没有,那么新的线段树 位置就赋成第一棵树的 的权值 ,返回。
相反的,如果第二棵树有一个 位置,但是第一棵数没有,那么新的线段树 位置就赋成第二棵树的 的权值,返回。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
| int merge (int a, int b, int cl, int cr)
{
if (!a) return b;
if (!b) return a;
if (l == r)
return a;
int mid = cl + cr >> 1;
tree[a].ls = merge (tree[a].ls, tree[b].ls, l, mid);
tree[a].rs = merge (tree[a].rs, tree[b].rs, mid + 1, r);
push_up (a);
return a;
}
|