落第骑士并查集
以我的最弱,击败你的最强。——《落第骑士英雄谭》
并查集
并查集的概念
并查集(Union-find Disjoint Sets)是一种简洁而又不失优雅的数据结构之一,主要用于解决一些元素分组的问题。它管理一系列不相交的集合,并支持两种操作:
1、合并(
2、查找(
这就好像一个家族问题,查询两个人是否有血缘关系(还好不是问我各个亲戚之间该叫什么,我可记不住这类乱七八糟的东西,每年探望亲戚前还要问一遍我妈 www )
这类问题只要建立模型,把所有元素划分到若干个不相交的集合里,使用并查集进行维护就可以了。
并查集的引入
并查集的重要思想就是,用集合里的一个元素来代表这个集合,我们将这个点称为父节点,现在我们来看一下并查集的过程。
刚开始,所有元素都互不相交,所以它们各自构成了一个集合,所有集合的父节点都是自己,它们互是自己的大哥:
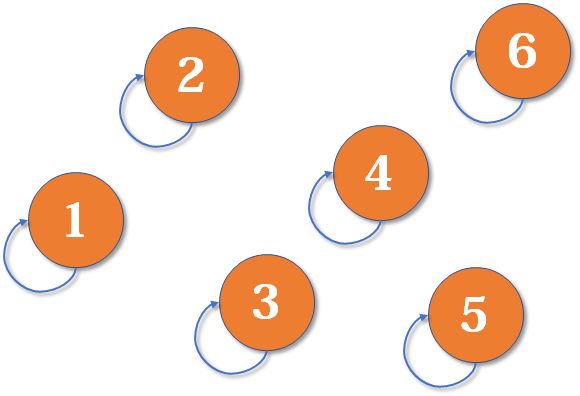
现在假设
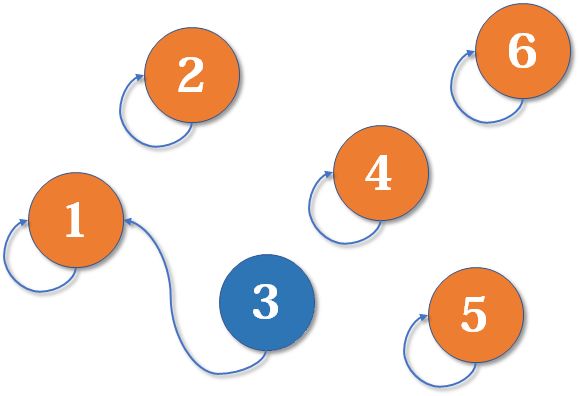
现在
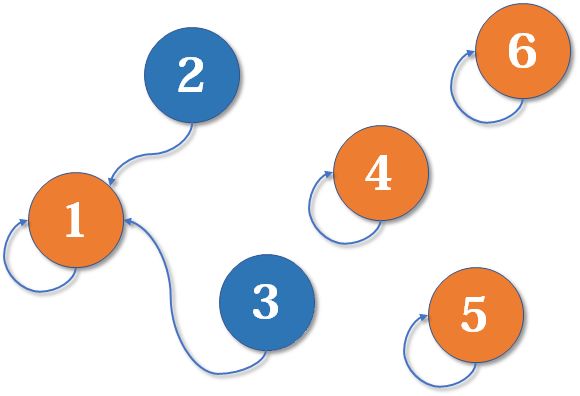
接下来假设
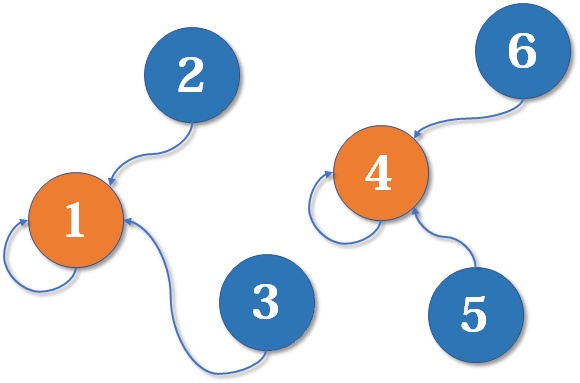
最后,假设现在
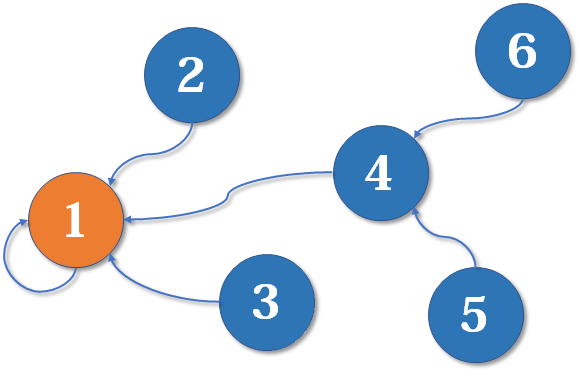
结束了,如果你仔细观察,就会发现这是一个树状结构,要寻找集合的代表元素,就要一层一层向上寻找父节点(图中自己指着自己的点)。根节点的父亲是它自己,我们可以直接把这张图画成一棵树:
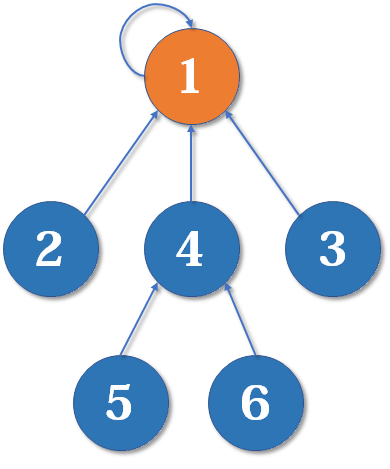
用这种方法,我们可以实现最简单的并查集。
并查集的食用
初始化
还记得我们说的吗,刚开始,每个元素都是自己的父节点。所以我们用一个数组
1 | int fa[maxn]; |
查询
查询的过程就是在集合这棵树上找自己的根节点,我们使用递归的方法来一层一层向上寻找父节点,直至根节点(这个集合的代表)。如果要判断两个元素是否在同一个集合内,只要询问它们的根节点是否相同就可以了。
1 | inline int find (int x) // 查询 |
当然我们也可以使用三目运算符将其合成为一句话。
1 | inline int find (int x) // 查询 |
合并
合并操作就是先找到两个点的根节点然后将其合并,前者是后者的父节点或者后者是前者的父节点都没有关系,后面我们会讲到一个更合理的合并方法。
1 | inline void merge (int x, int y) // 合并 |
路径压缩
最简单的并查集效率是比较低的,先来看一个场景:
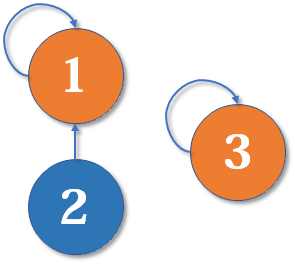
现在我们要

然后我们找到了
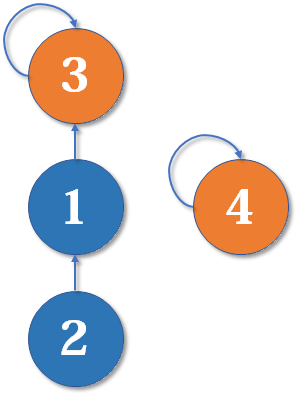
从

这样就变成了一条链,显然随着链的长度的增加,想要从子节点找到根部的难度也变大了。
所以这里使用到路径压缩。既然我们只关心一个元素对应的根节点,那么我们希望步数尽量少,最好只有一步(贪到家了啊喂!!!),就像这样:

实现方法很简单,只要我们在查询的途中,把沿途的每个节点的父节点都设为根节点即可(从间接管辖变到了直接管辖)。
代码如下:
1 | inline int find (int x) // 查询 |
当然通常简写成一行(压行大师):
1 | inline int find (int x) // 查询 |
注意赋值运算符的优先级没有三目运算符高,要加括号。
按秩合并
注意,路径压缩后不等于并查集是菊花图(只有两层的图的俗称),而且只有路径压缩只在查询时进行,也只压缩一条路径,所以并查集的结构最终还是很复杂的,如下图,我们现在有一棵较复杂的树要和一个单元素的集合合并:
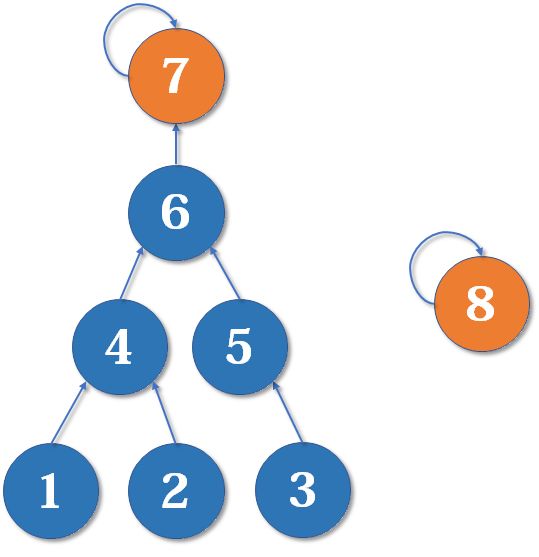
此时是把
当然都不是!(大雾,难道不是把
来看一下两种情况:
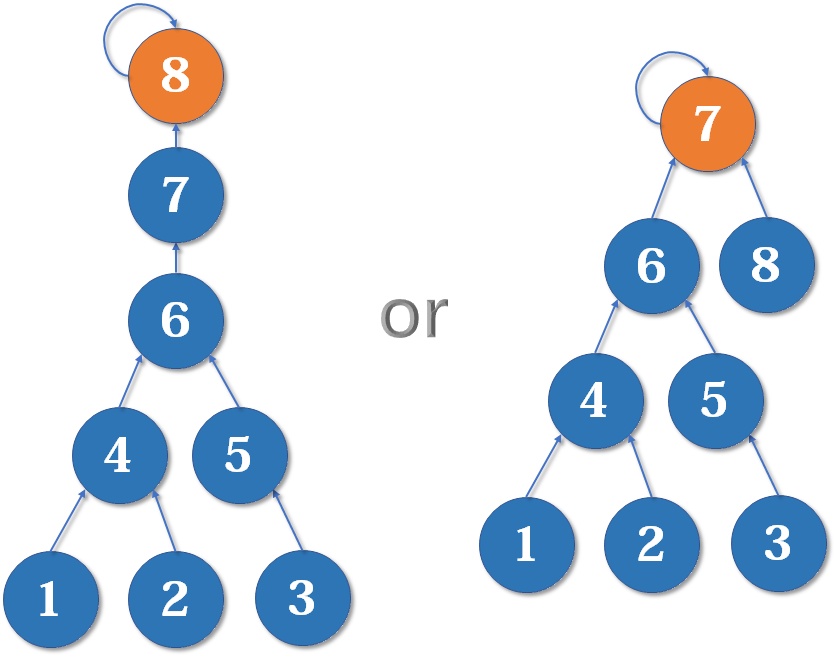
如果是第一种情况,会导致树的深度(树中最长链)增长,会增加时间;但是第二种情况的
所以我们应该把简单的树合并到复杂的树上,这样可以适当减少到根节点距离长的点的个数。
实现方法就是用一个数组
路径合并如果和按秩合并一起使用,时间复杂度接近
初始化
1 | void init () |
合并
1 | inline void merge (int x, int y) |
试问,为什么当深度相同的时候,新的根节点深度要加一?
假设现在我们有两棵深度为
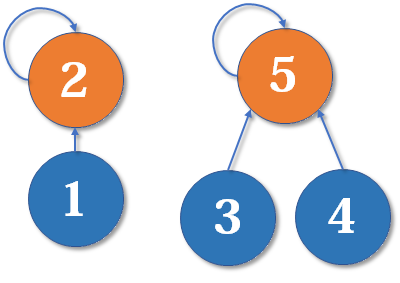
这里把
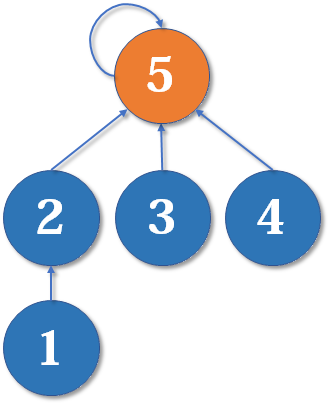
显然这棵树的深度加一,另一种合并方式同样会使深度加一。