即使失去了重要之物,少年仍然直面命运。即使忘记了重要的人,怪物仍然挑战命运。——《Charlotte》
Knuth Morris Pratt
真的没名字能代进去了,《 》和《 》在这种情况下真的是不好搞。
KMP算法(全称 字符串查找算法,由三位发明者的姓氏命名)是可以在文本串 中快速查找模式串 的一种算法。
暴力匹配
显然,既然我们会讲这个算法,就是因为暴力匹配太慢了!!!
但是我们还是应该不厌其烦地看看暴力匹配是如何浪费时间,如果你在比赛中忘记了怎么写 的时候,说不定暴力也是一种骗分的好办法(为什么不用 呢),而且这段浪费时间的文字成为了我们进步的基石。
所谓暴力匹配,就是逐字符逐字符的进行匹配,如果当前字符匹配成功,就匹配下一个,如果失配(在刺客信条里我们通常称为失去同步),回溯,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| int i = 0, j = 0;
for (auto i : s)
{
if (s[i] == p[j])
++ i, ++ j;
else
{
i = i - j + 1;
j = 0;
}
if (j == p.length ())
{
printf ("%d\n", i - j);
i = i - j + 1;
j = 0;
}
}
|
如果我们暴力匹配 ” “,会发生什么呢?
从头开始匹配,第一位字符成功:
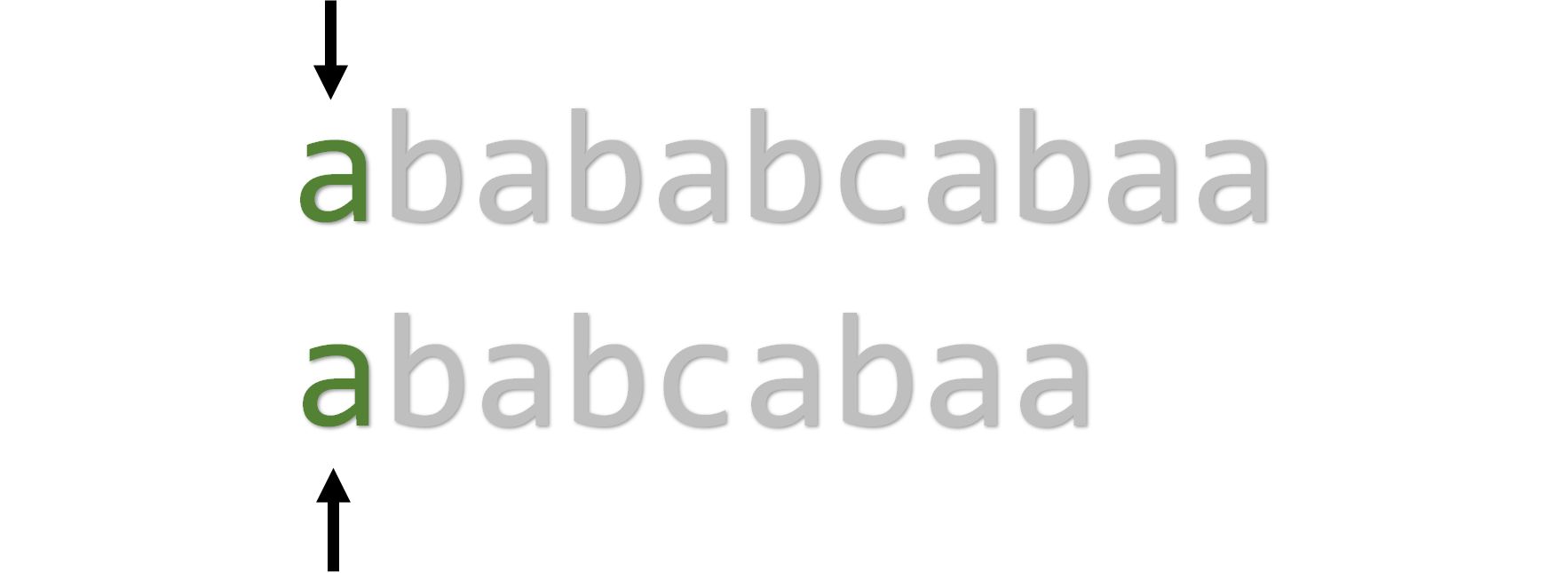
第二到四位字符也匹配成功,继续:
 下一位,匹配失败,回溯:
下一位,匹配失败,回溯:
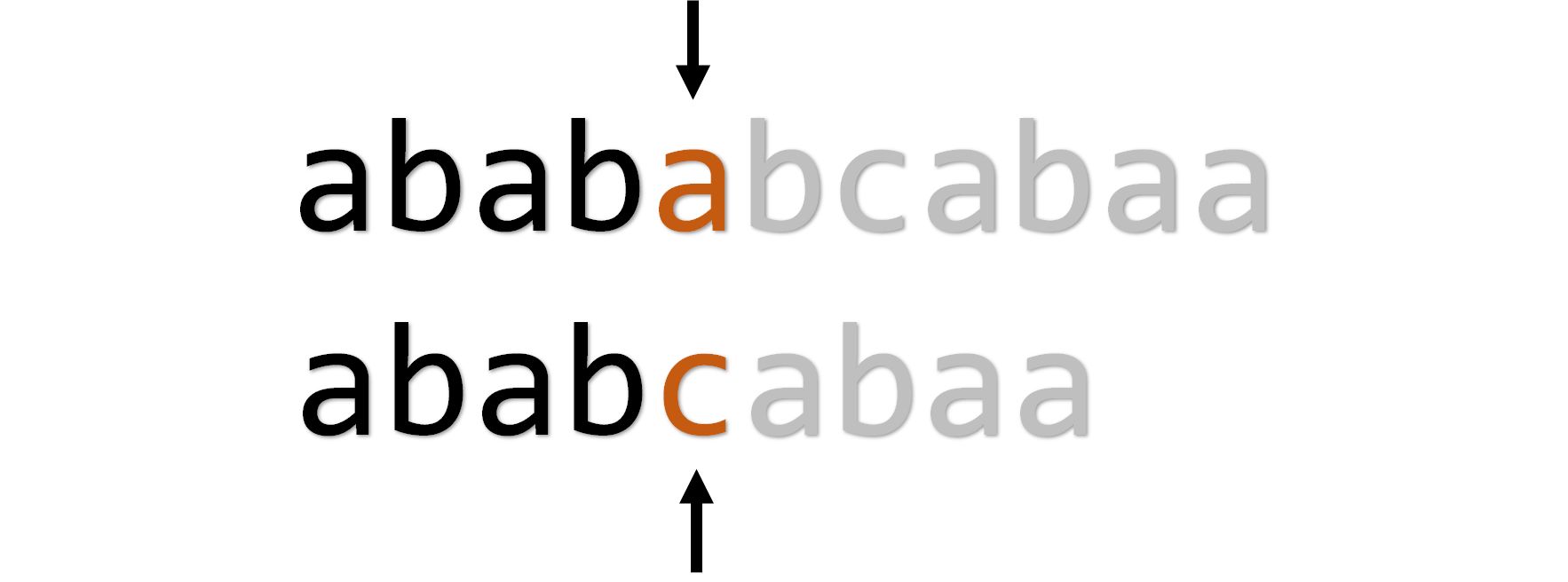
匹配失败,继续尝试:
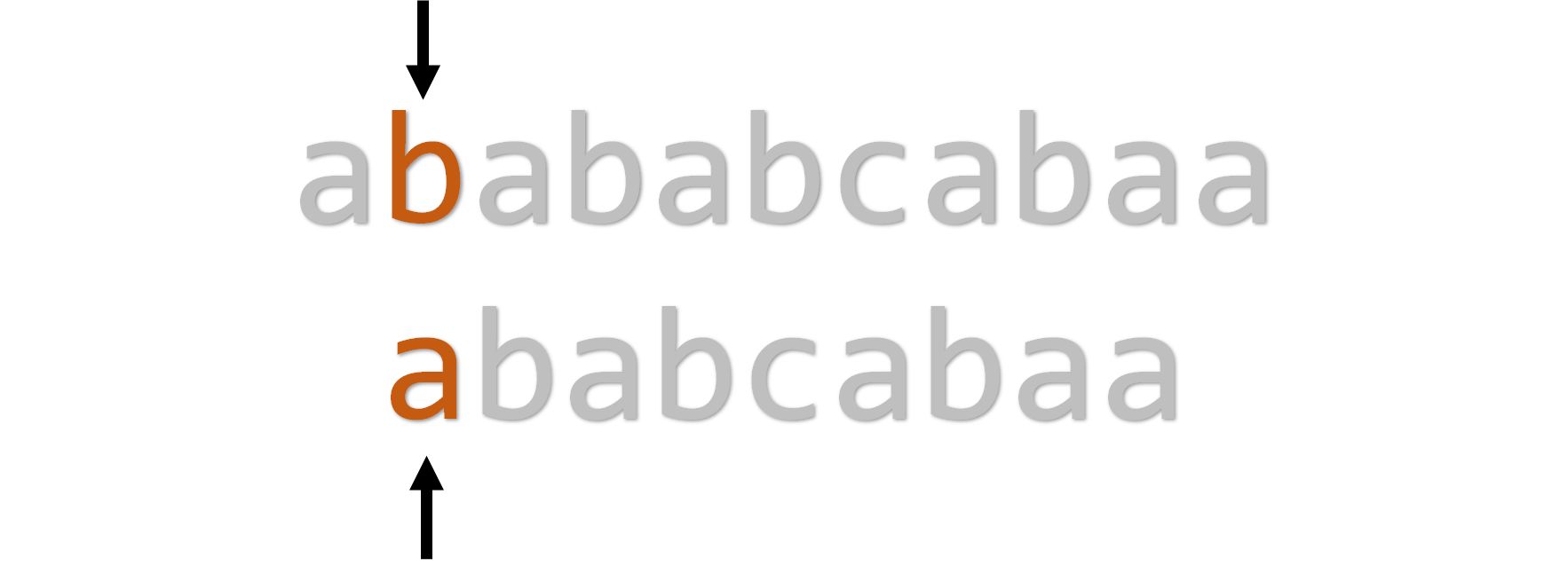 下一位匹配成功了!
下一位匹配成功了!

就这样一直啪塔啪塔地匹配到字符串の尽头:
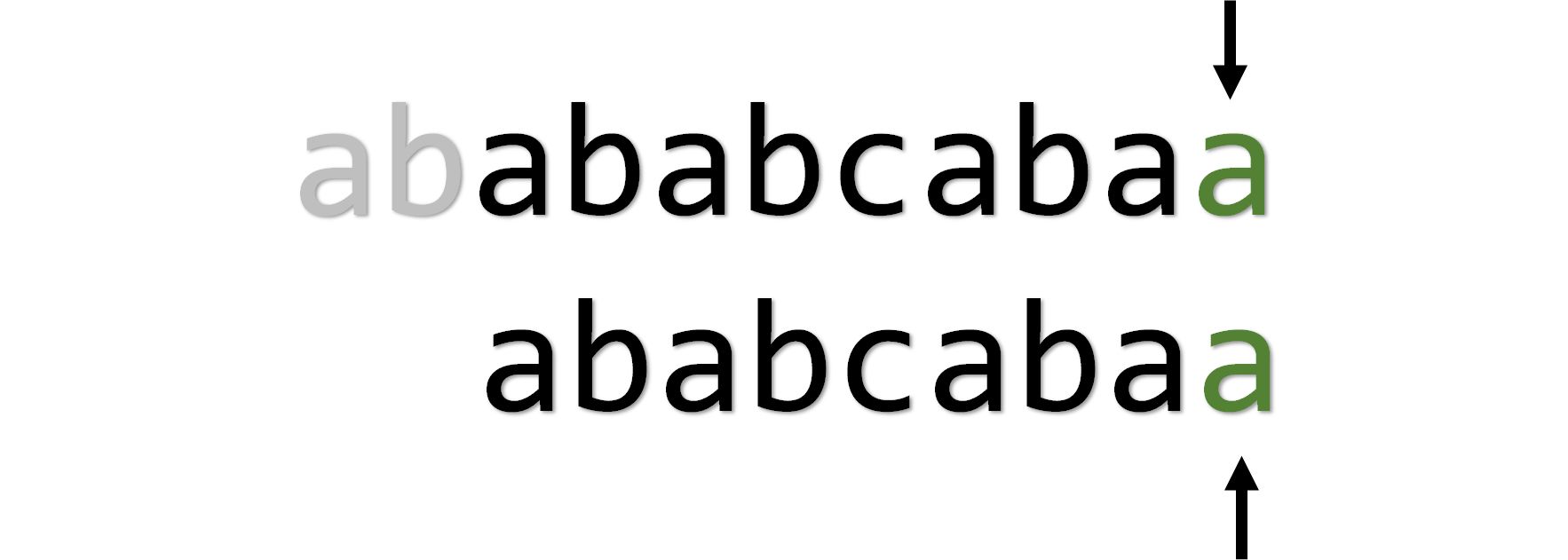
设两个字符串的长度分别为 和 ,则暴力匹配最坏时间复杂度是 。究其原因,是 在回溯的时候浪费了时间,但是如果不回溯,还把光标置零,很可能会出现遗漏,如下图:
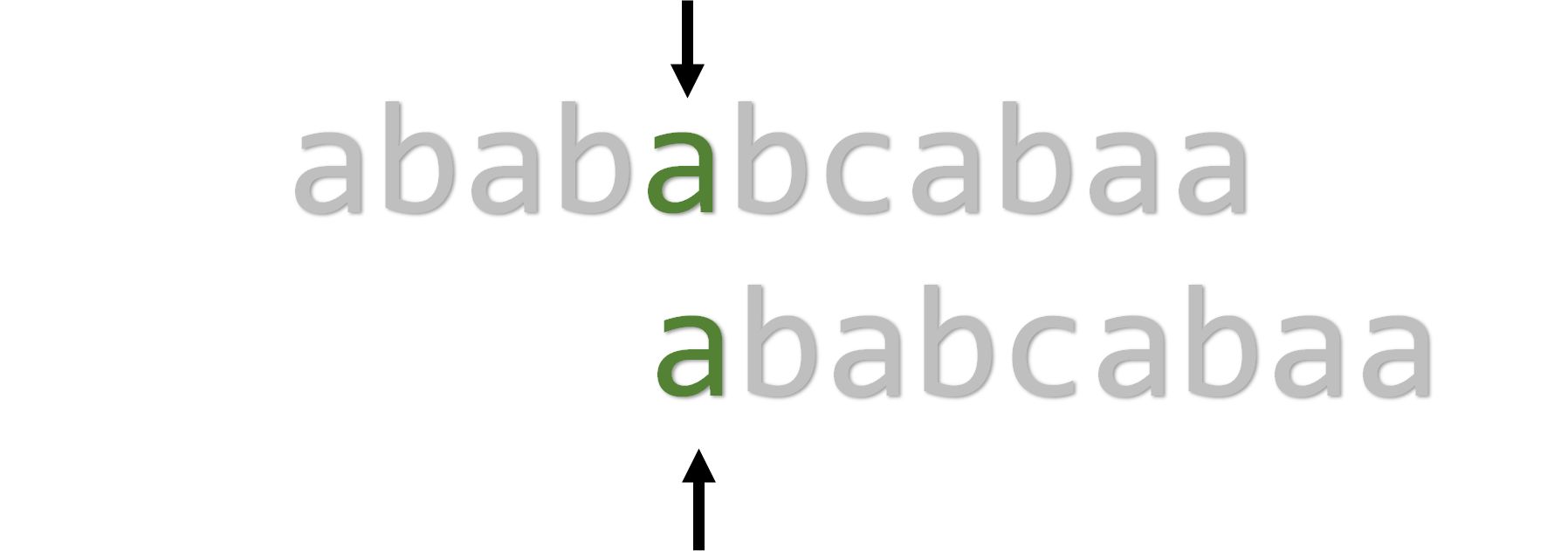
于是为了让光标被赋为一个合适的值,我们引入了PMT( ,部分匹配表)
部分匹配表
原理
光标应该被赋值为多少,是只与模式串自身有关的。每个模式串,都对应着一张 ,比如 “ “对应的 如下:

观察后可以发现, 就是,从 开始数、同时从 往后数相同的位数,在保证前后缀相同的情况下,最多能数多少位。

专业一点说,它是真前缀(不包含字符串本身的前缀)和真后缀(不包含字符串本身的后缀)的集合之交集中,最长元素的长度。
为什么 可以用来确定指针的位置呢,让我们先时间回溯到暴力匹配第一次失配的那个时候:
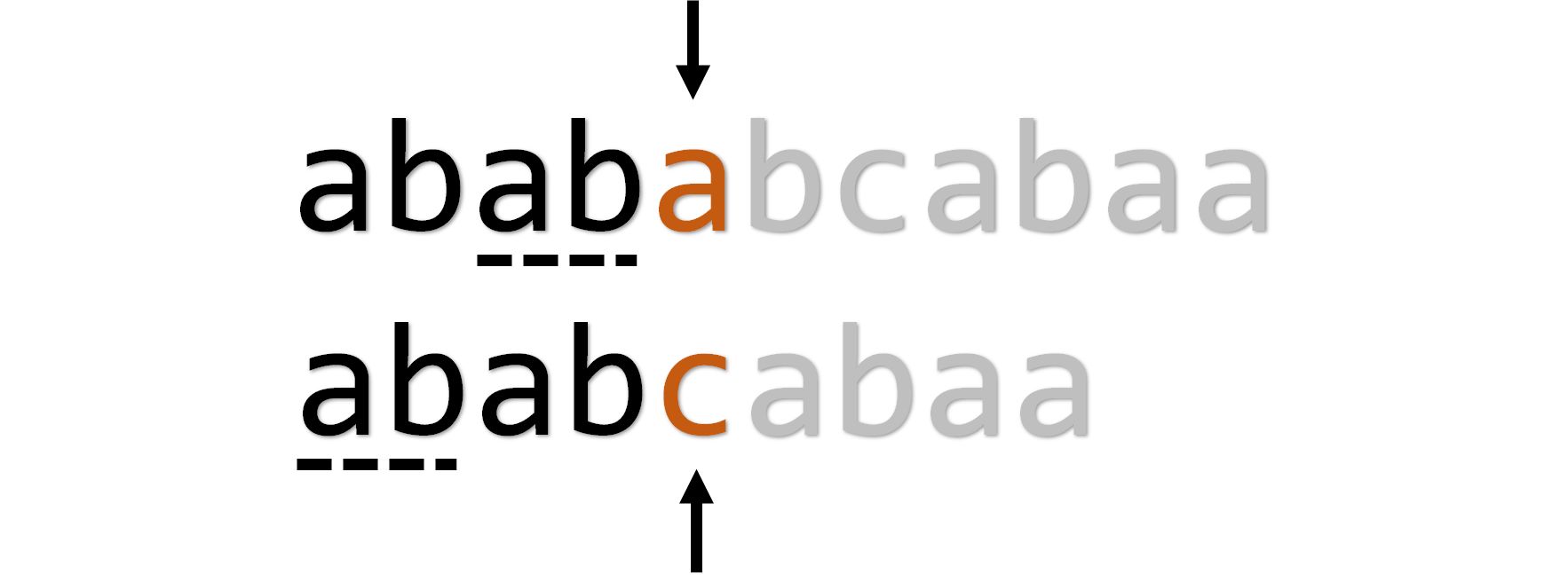
这时,字符串 中的’ ‘和字符串 中的’ ‘没有匹配,那么我们刻意改动时间线保持上面的指针不变,把下面的指针左移。这时注意到,” “已经匹配成功了,它拥有一个前缀” “和一个后缀” “(两个虚线部分),所以可以把这个” “利用起来,变成下面这样:

实际上这个时候我们正是在令 。再举一个例子:
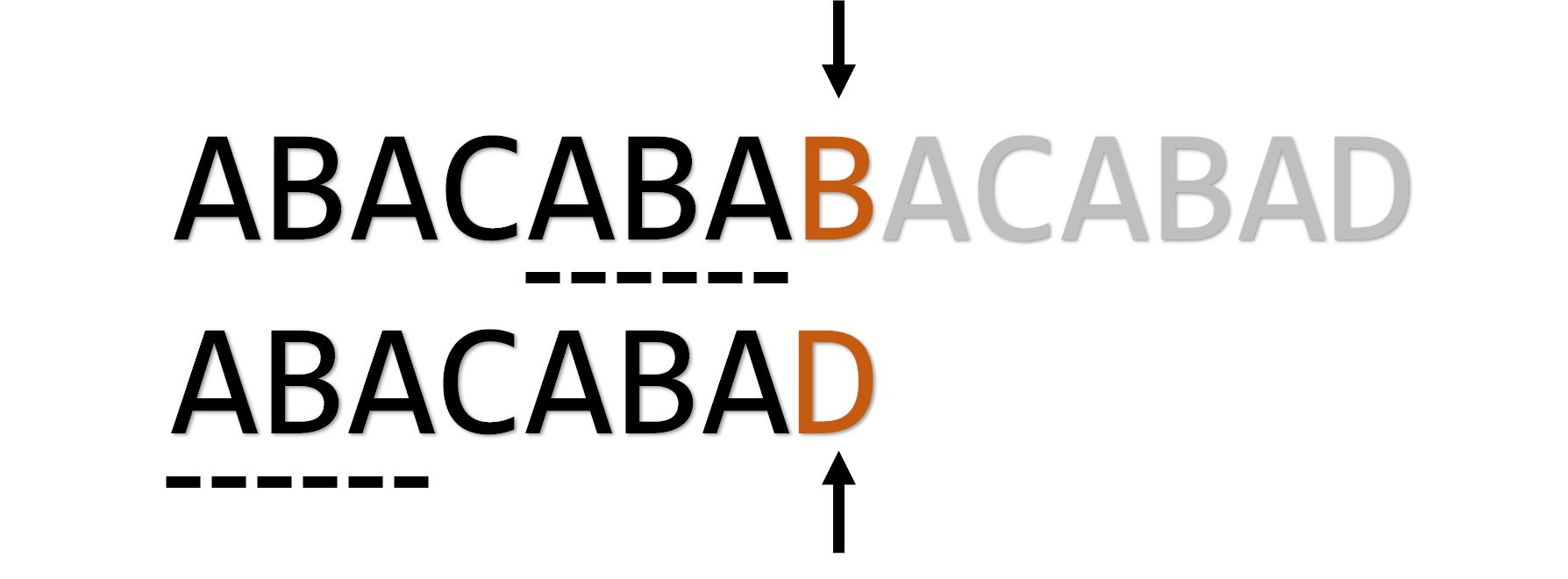 发生失配,我们令 (也就是符合条件的最长前缀(最大匹配)所紧接着的下一位):
发生失配,我们令 (也就是符合条件的最长前缀(最大匹配)所紧接着的下一位):
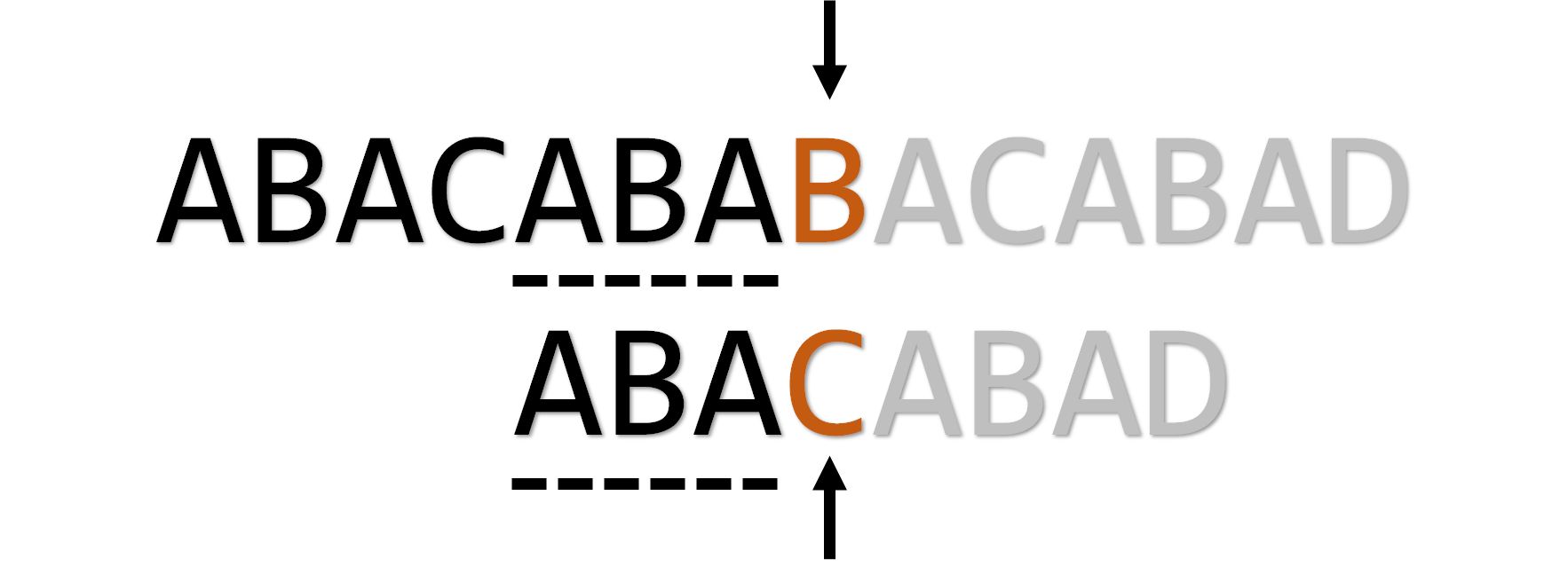 仍然不匹配,继续遍历:
仍然不匹配,继续遍历:

现在是 ,然后匹配:
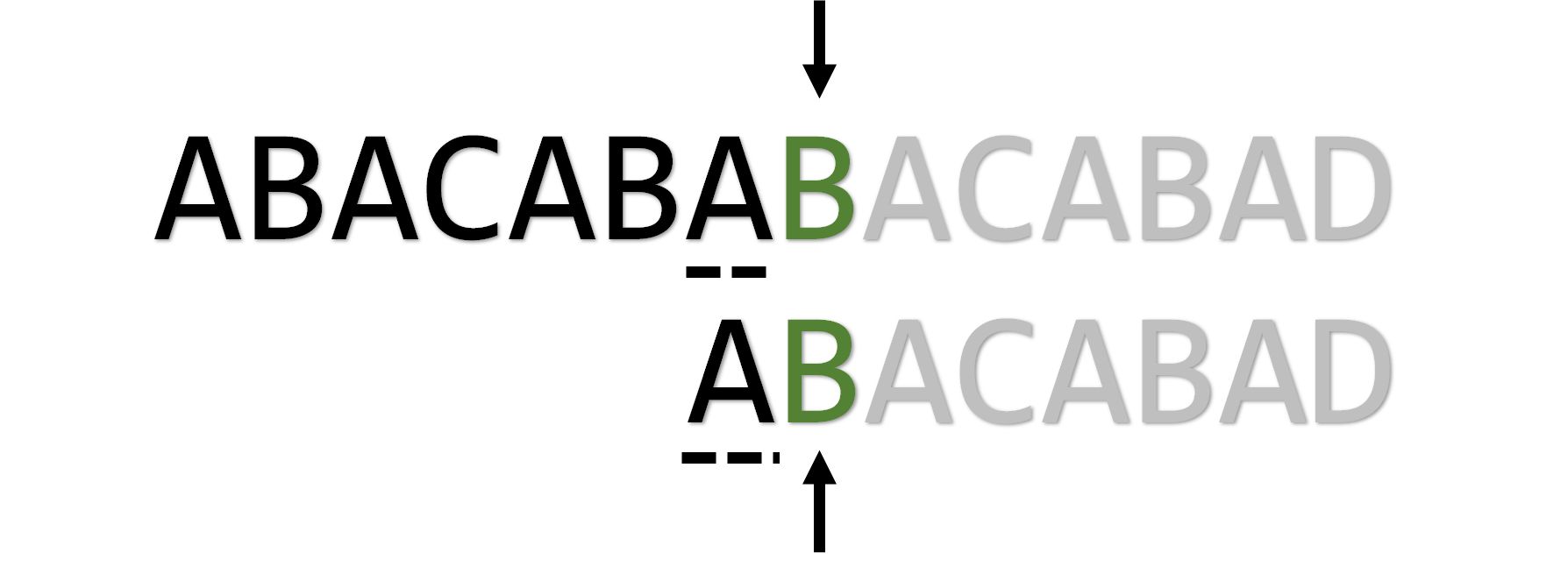
这次取得了匹配,继续匹配下去我们就可以非常幸运地得到答案了,现在我们将其转化为代码:
1
2
3
4
5
6
7
8
9
10
11
| for (int i = 0, j = 0; i < s.length (); ++ i)
{
while (j >= 0 && s[i] != p[j])
j = j ? pmt[j - 1] : -1;
++ j;
if (j == s.length ())
{
printf ("%d\n", i - j + 1);
j = pmt[j - 1];
}
}
|
如果到这里你仍不知道为什么 的话,因为 前面的 是匹配的(即存在 ),所以 其实是等于最大匹配长度的,那么就会回到 ,也就是回到前缀。
很多文章中会出现 数组,即把 整体向右移一位(特别的,令 ),表示在每一位失配的时候应跳转到的索引。也就是说,失配时,按照 的顺序跳转。
获取
现在问题来了, 怎么求?如果暴力求的话,时间复杂度是 ,并不理想。神奇的是,我们可以在错开一位后,让 自己匹配自己(等于是用前缀匹配后缀),我们知道 ,而之后的每一位则可以通过匹配过程中记录 值得到。
还是以刚刚的模式串为例:
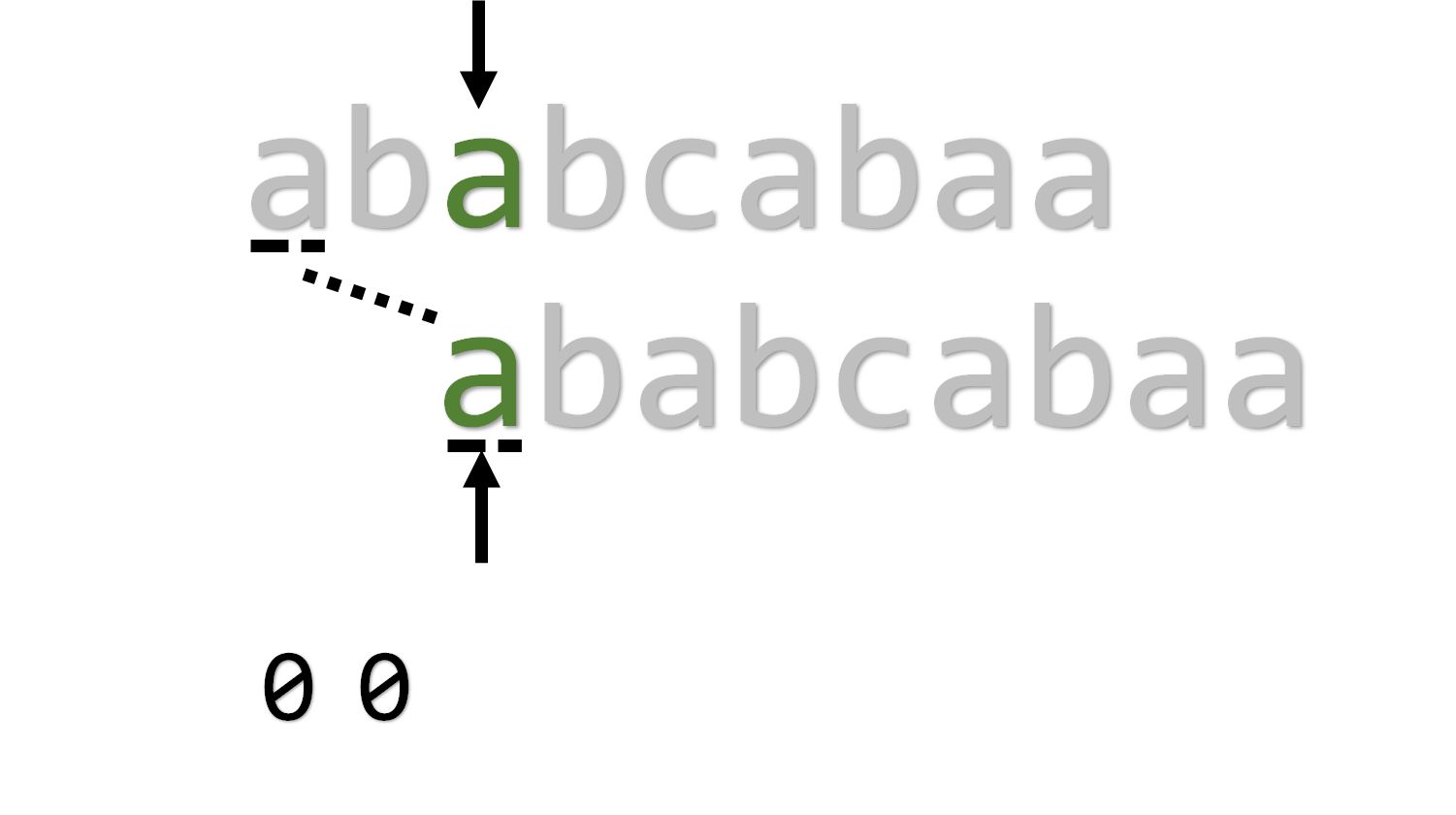
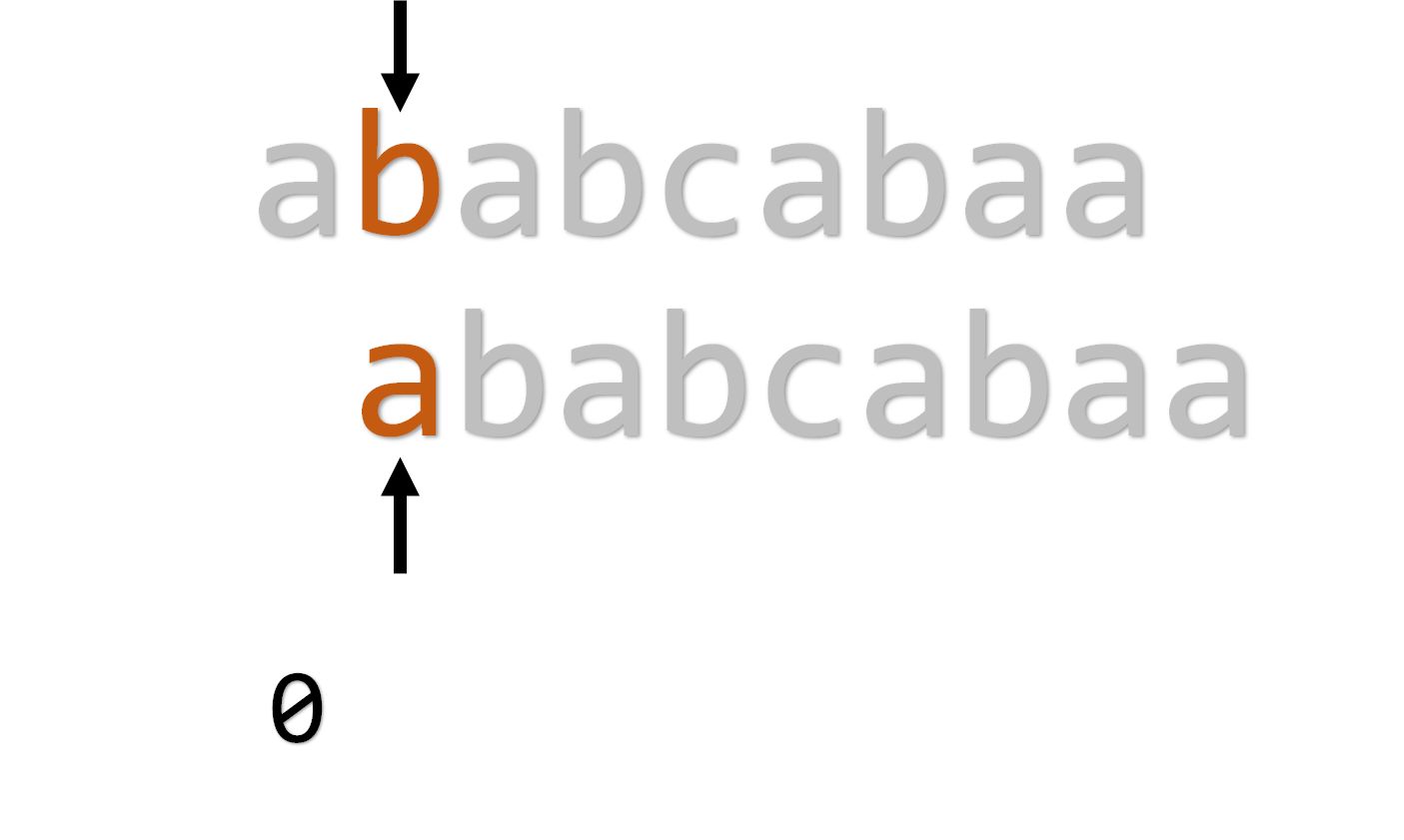 匹配失败,则 , 指针后移。
匹配失败,则 , 指针后移。
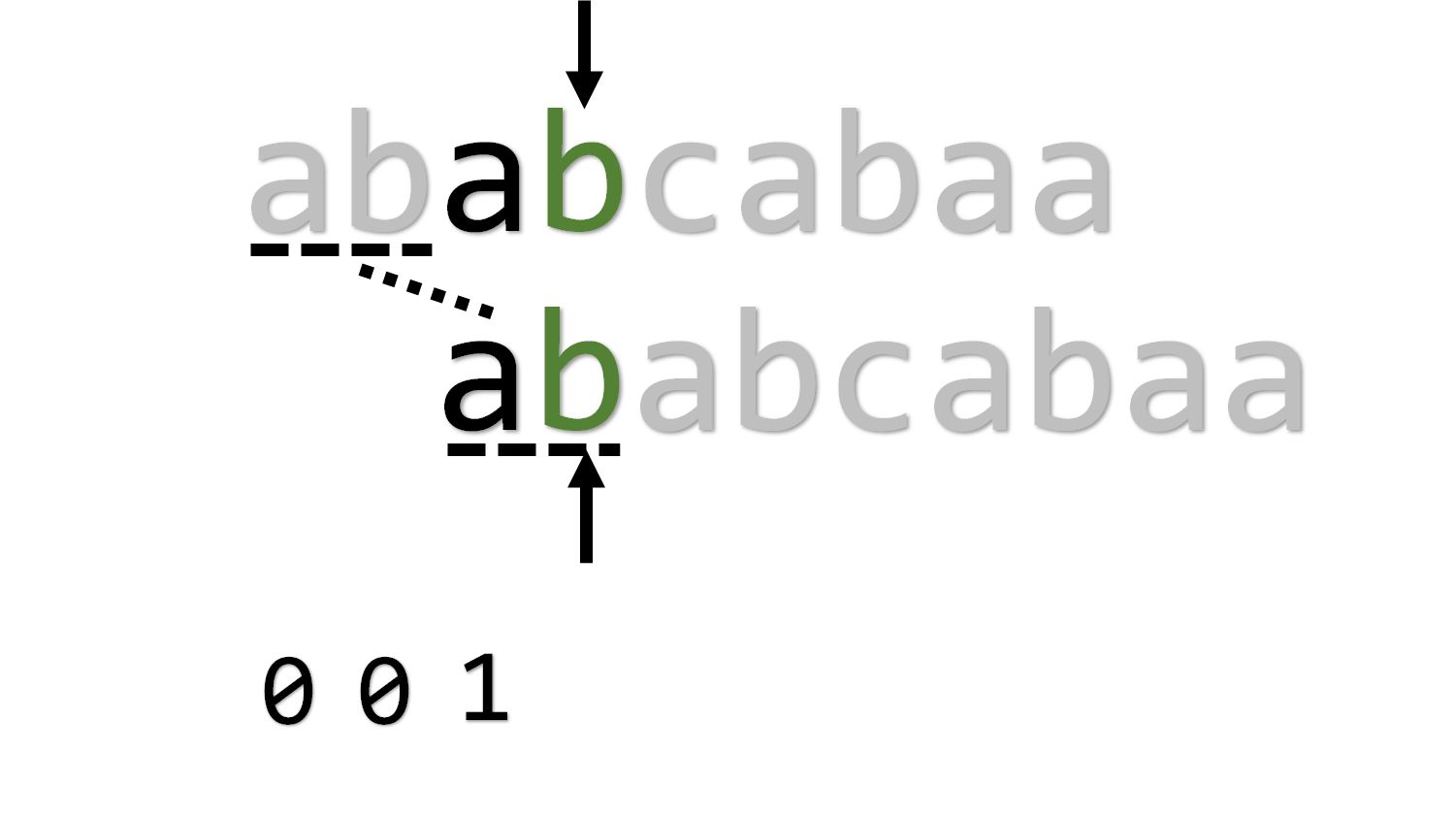
 接下来匹配成功,得到 ,然后将两个指针都右移。
接下来匹配成功,得到 ,然后将两个指针都右移。
 继续匹配成功, 。
继续匹配成功, 。
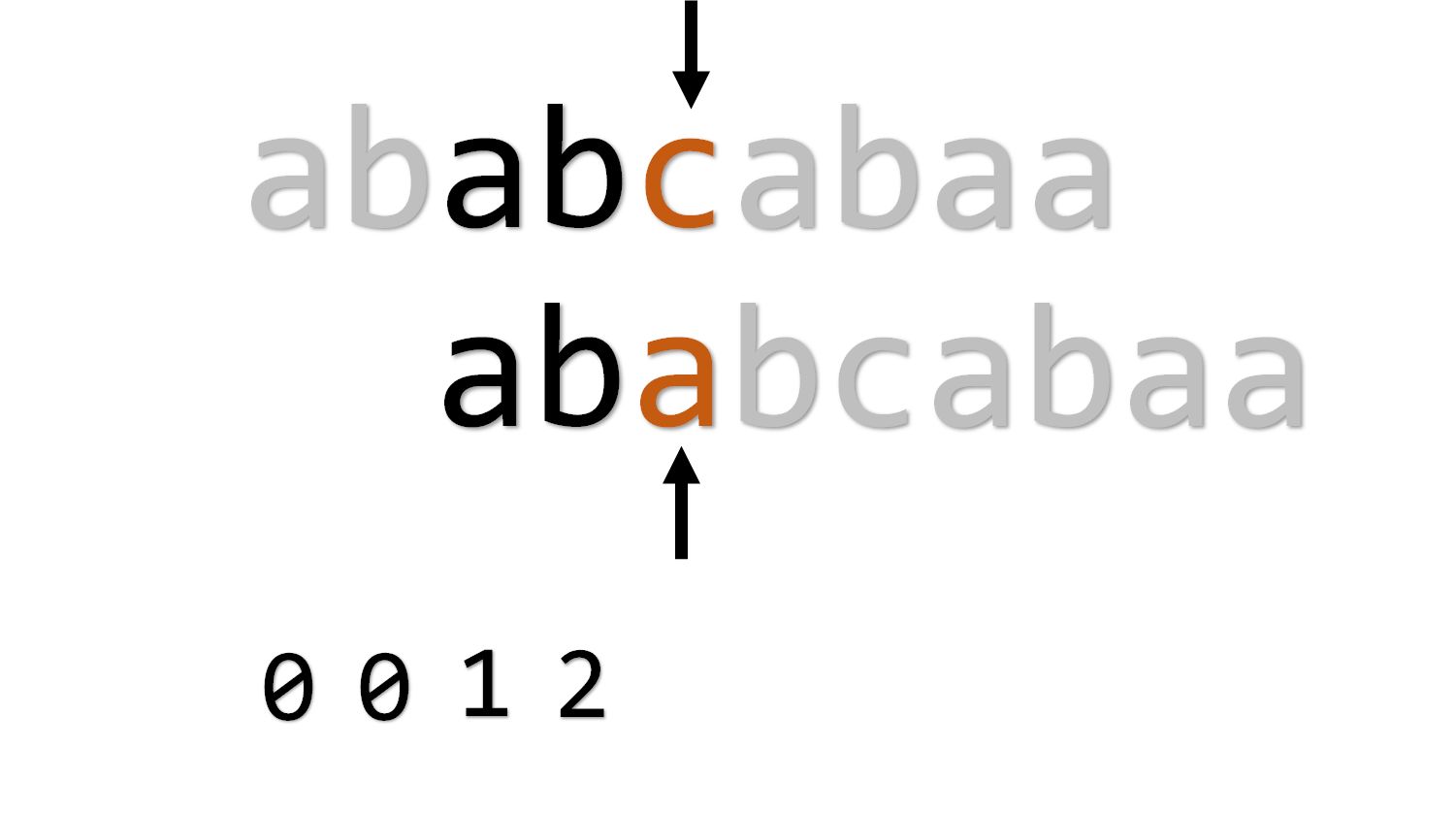 下一位又失配了,但是因为前面的 已经算出来了,我们可以像匹配文本串一样使用它。 即 等于 ,所以退回开头。
下一位又失配了,但是因为前面的 已经算出来了,我们可以像匹配文本串一样使用它。 即 等于 ,所以退回开头。
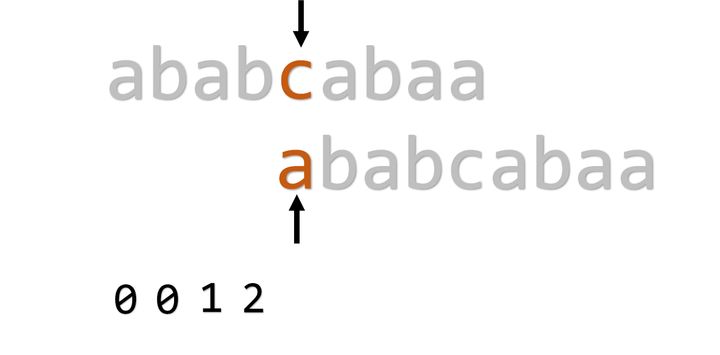
结果在开头匹配失败了,出师不利,则 。接下来也按这样操作:
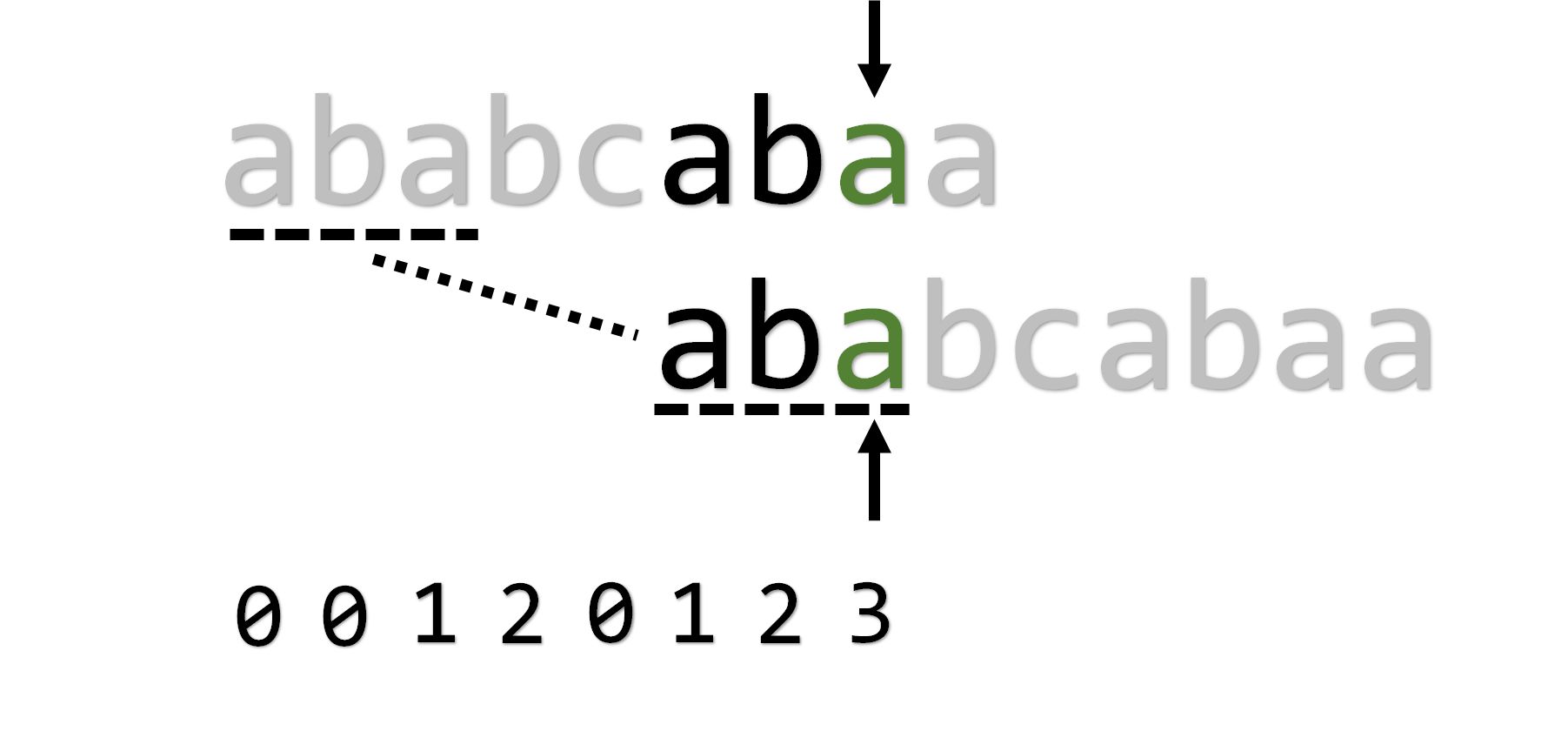 最后一位出现失配,这次是先令 ,也就是直接回到老家:
最后一位出现失配,这次是先令 ,也就是直接回到老家:
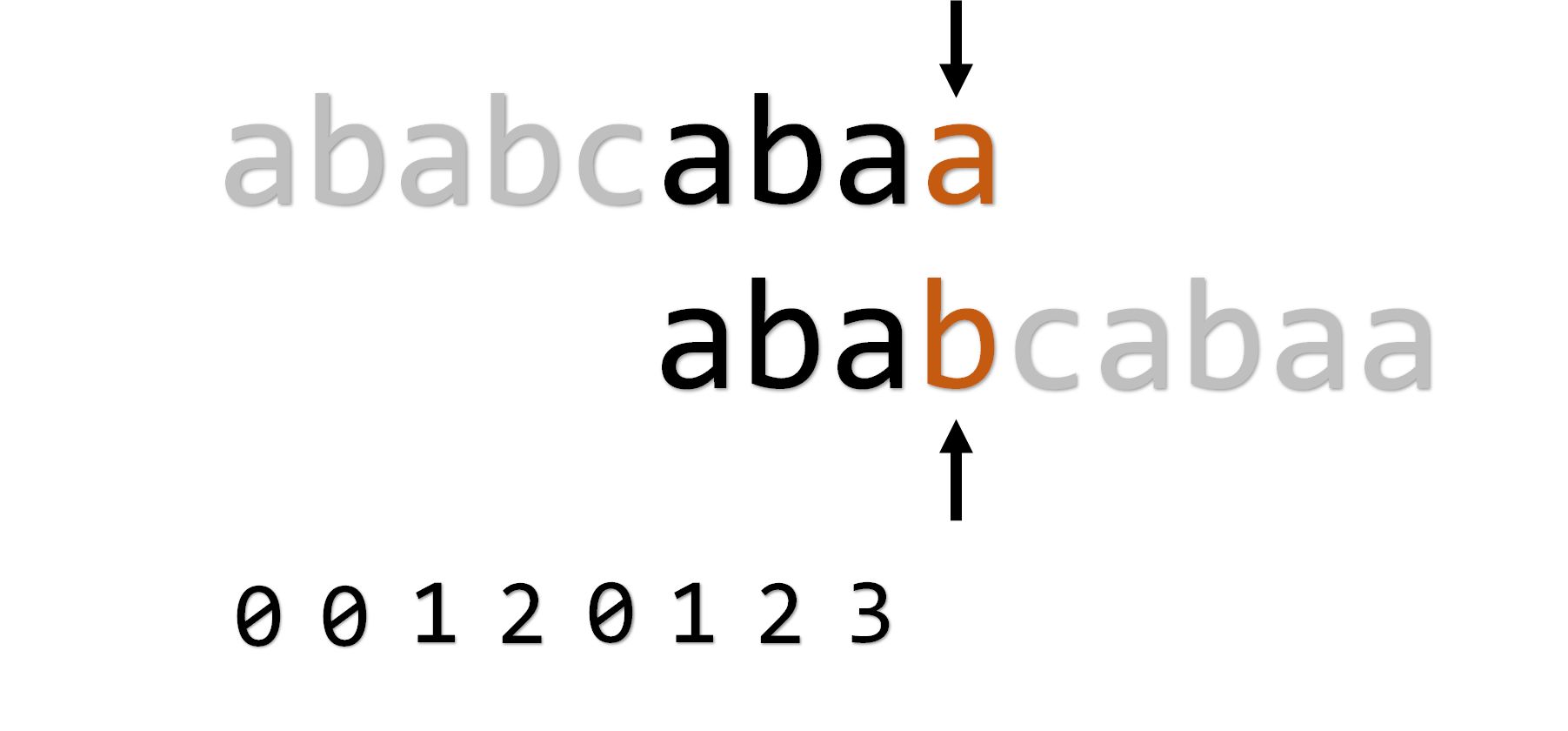 那么直接回到老家:
那么直接回到老家:
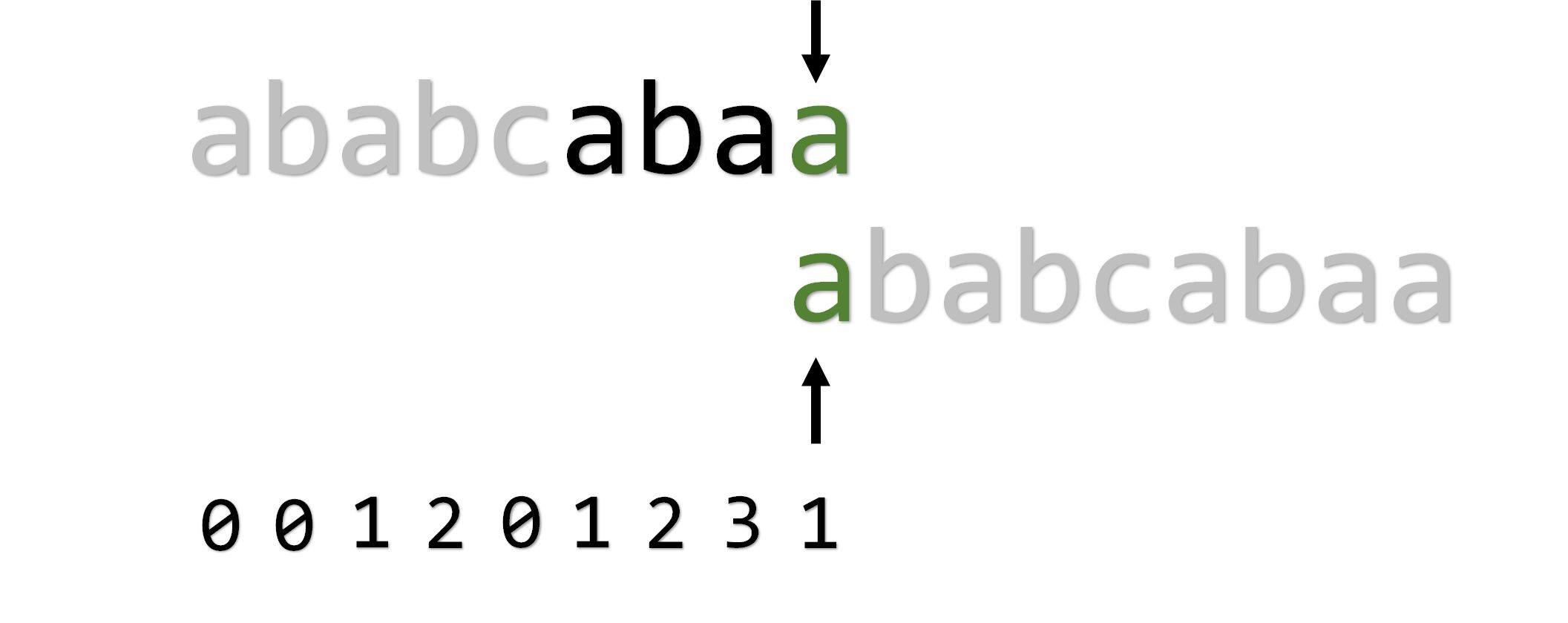 再次匹配,匹配成功。自此,通过一次自我匹配,求出了 ,代码如下:
再次匹配,匹配成功。自此,通过一次自我匹配,求出了 ,代码如下:
1
2
3
4
5
6
7
| pmt[0] = 0;
for (int i = 1, j = 0; i < p.length (); ++ i)
{
while (j >= 0 && p[i] != p[j])
j = j ? pmt[j - 1] : -1;
pmt[i] = ++ j;
}
|
优化
上面的只能被称作 算法,一切从现在开始。
例如对于” “这个模式串,如果我们用它来匹配” “,在最后要跳转 次才能发现匹配失败:
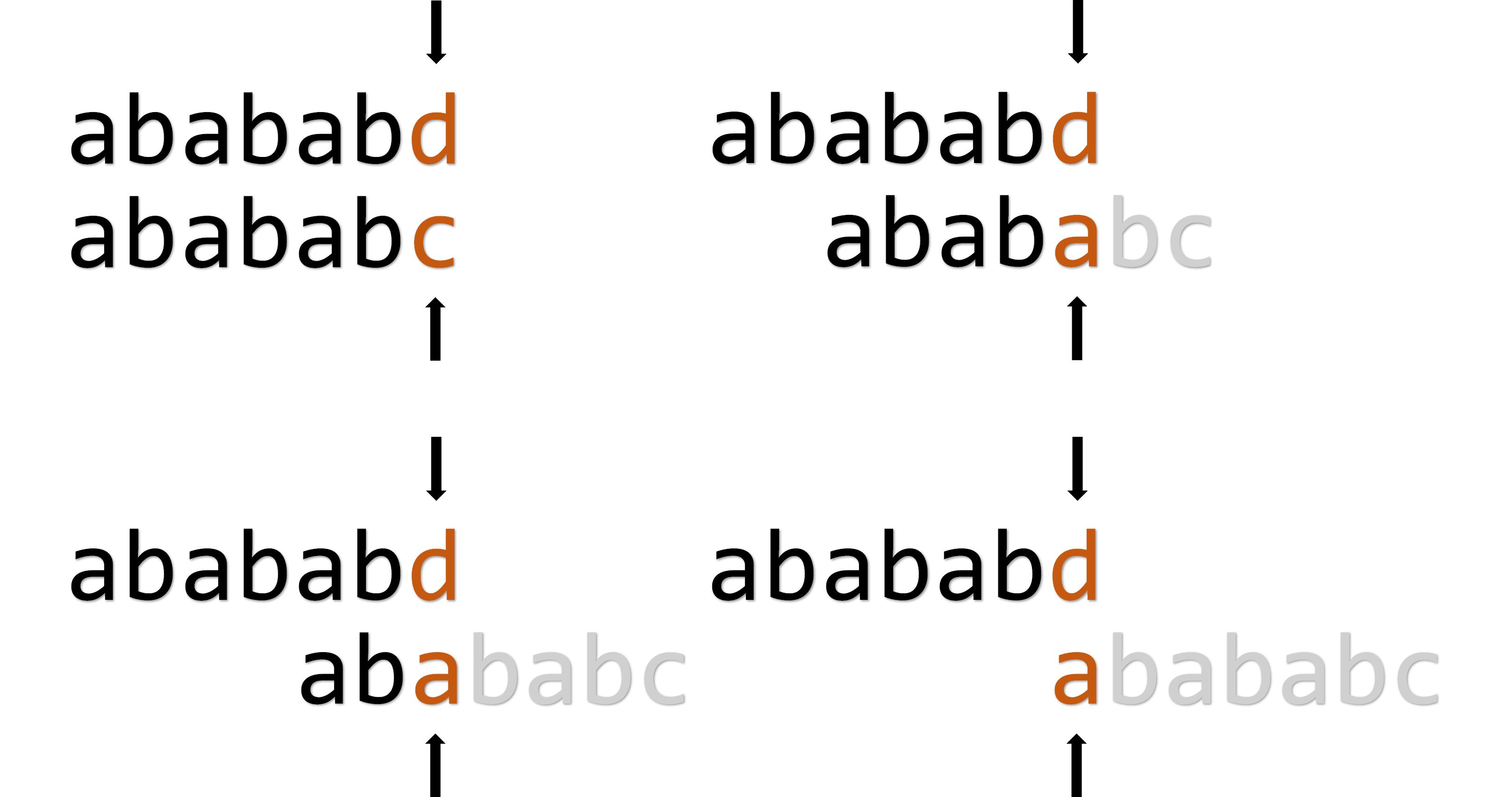
中间这几次跳转是毫无意义的,所以我们可以在计算 的时候动上一些小手脚:
1
2
3
4
5
6
7
| pmt[0] = 0;
for (int i = 1; j = 0; i < s.length (); ++ i)
{
while (j >= 0 && p[i] != p[j])
j = j ? pmt[j - 1] : -1;
pmt[i] = j >= 0 && p[i + 1] == [j + 1] ? pmt[j ++] : ++ j;
}
|
如果自我匹配成功了,第 位在失配的时会跳转到第 位,但是我们发现第 位和第 位的字符是一样的。我们直到第 失配后会跳转到 位即 位,所以干脆跳过 直接到 去。
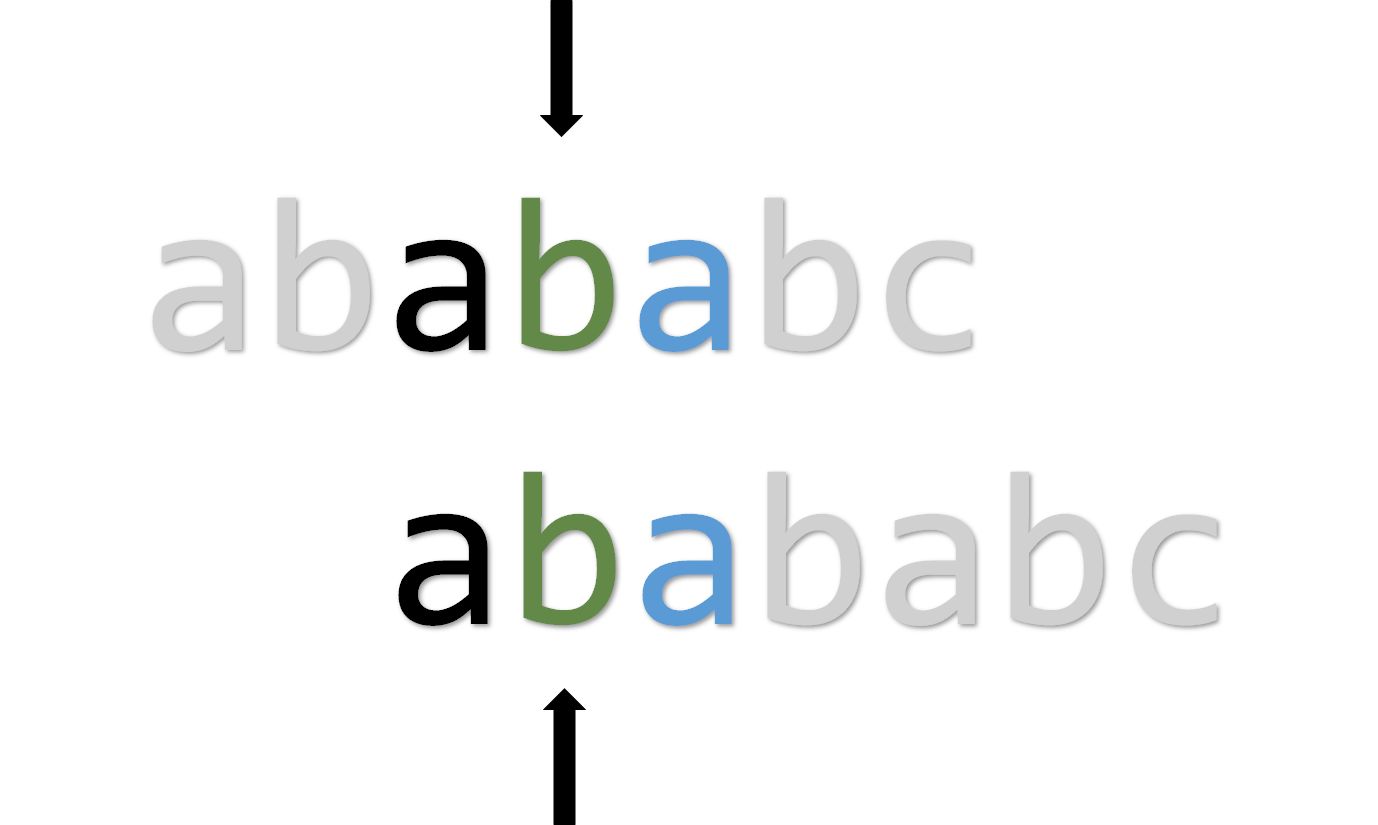
相反,匹配到下图时, ,就可以像之前那样处理。
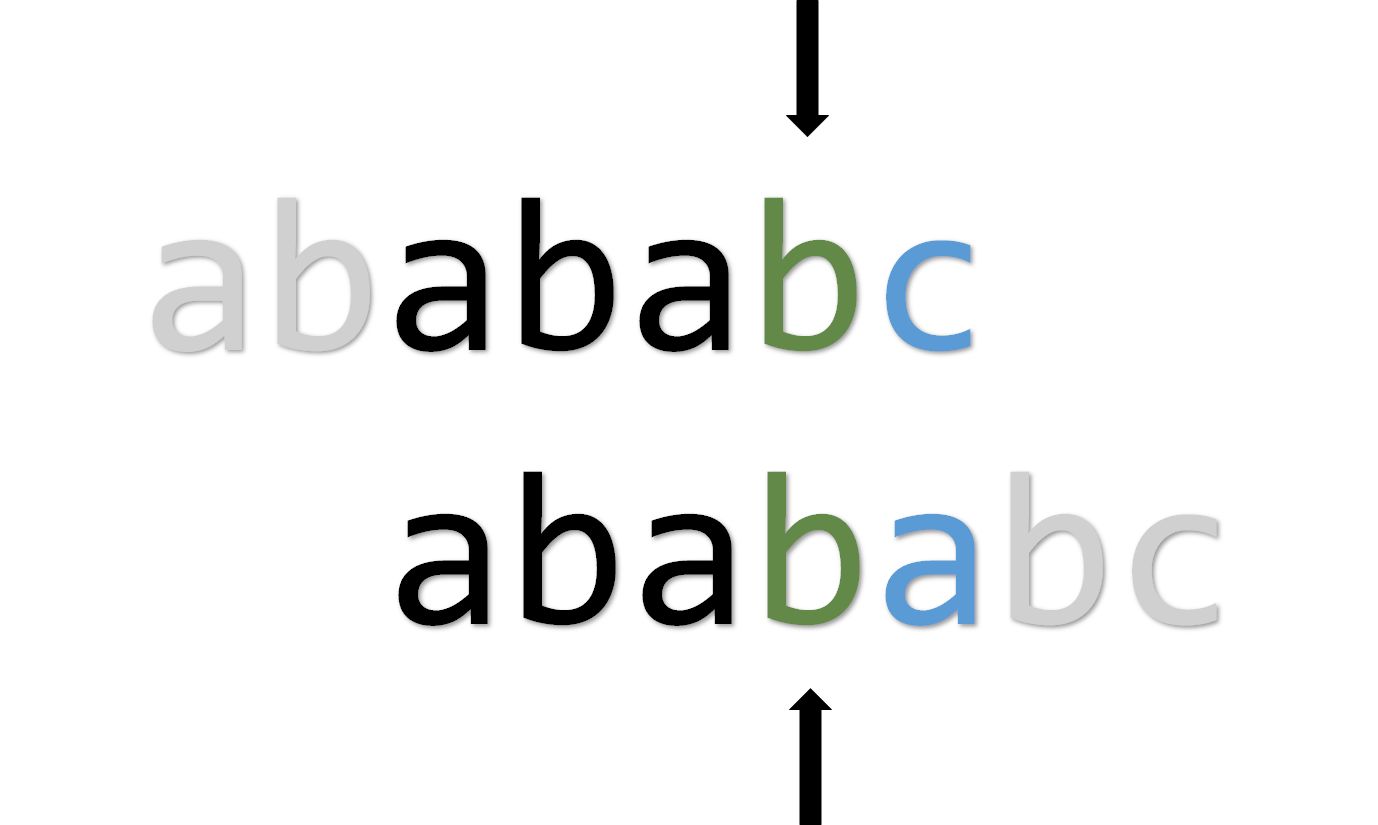
但是这个已经不叫 了(不信你自己试试去),这个应该重开一个数组 。
算法总的时间复杂度是 ,这是因为 和 都只进行了 次,虽然 在过程中有减小,但 在任何时刻不会小于 ,所以 减小的次数也不可能超过 。