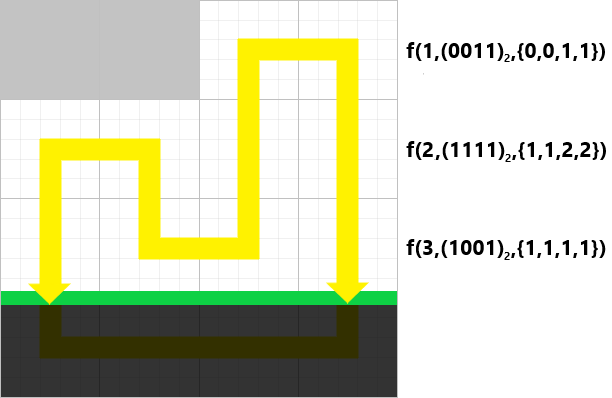
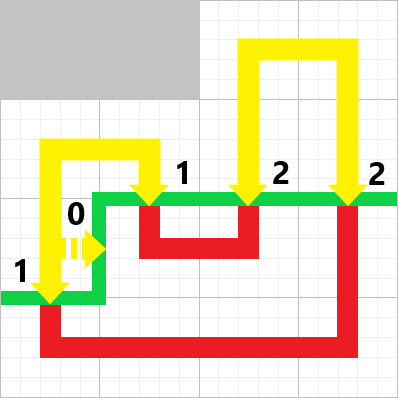
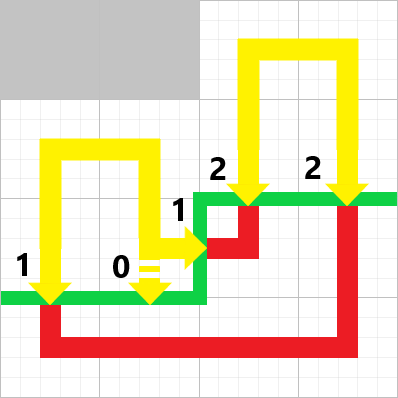
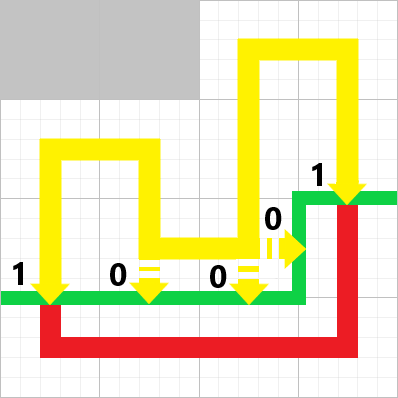
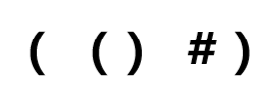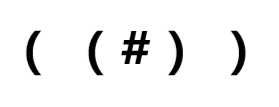就让我用这只手,将你那无聊的幻想杀得片甲不留。——《魔法禁书目录》
动态规划
动态规划(Dynamic Programming,DP) ,是运筹学 的一个分支,是求解决策过程中最优化的过程 。动态规划的应用及其广泛,包括工程技术、经济、工业生产、军事以及自动化控制等领域,并在背包问题、生产经营问题,资金管理问题、资源分配问题、最短路径问题和复杂系统可靠性问题等中取得了显著的效果。
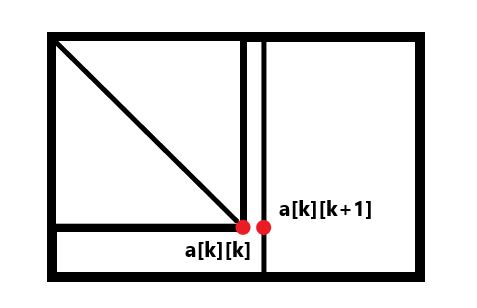
背包问题 背包问题( 是一种组合优化的
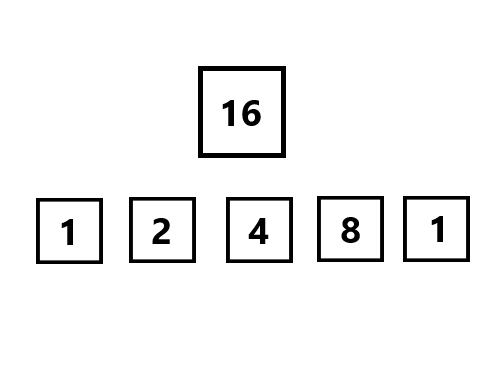
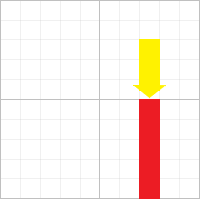
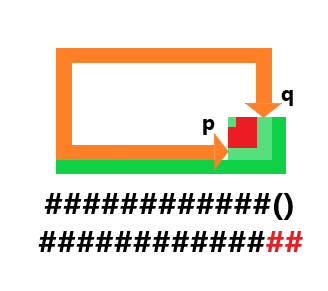
01背包 这是最简单的动态规划问题。
所谓 “ 每种物品只能选一次。
那么很显然,对于每个物品,只有拿或者不拿两者可能,对所有物品遍历,对于每个重量状态遍历,如果可以拿,就和不拿的情况进行对比,不拿就是不拿,仍等于前面的情况,所以就是拿就拿,不拿拉倒的一个简单思想。
那么尝试用
模板代码如下:
1 2 3 4 5 6 7 8 9 10 for (int i = 1 ; i <= n; i ++) { for (int j = m; j >= 0 ; j --) { if (j >= w[i]) f[i][j] = max (f[i - 1 ][j], f[i - 1 ][j - w[i]] + val[i]); else f[i][j] = f[i - 1 ][j]; } }
对于拿,从拿和不拿的状态中选择一个更优的 ,如果拿,就从前面的状态
对于不拿,不拿就是不拿,想拿都没法拿,怎么办也没法拿。
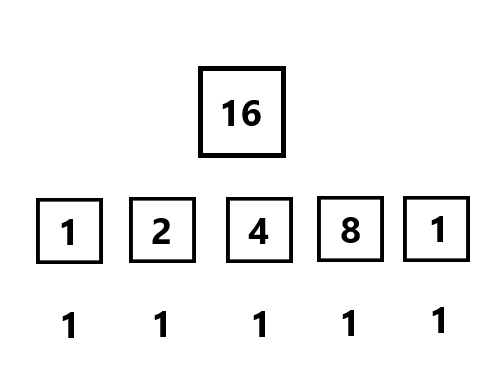
时间复杂度是 滚动数组优化 (可以滚来滚去骨碌骨碌转的数组哟~)
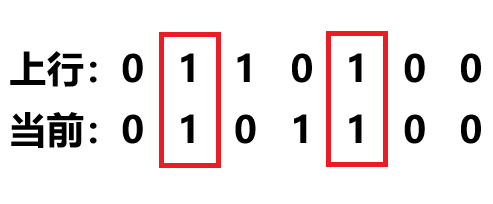
滚动数组 接下来我们要用一维数组代替掉非常糟糕的二维数组!
看到前面的状态转移方程:
1 f[i][j] = max (f[i - 1 ][j], f[i - 1 ][j - w[i]] + val[i]);
那么一个很显然的事实就是,为了得到现在的状态
当我们使用一维数组存储状态时,
为了求
至于这里逆序枚举容量 的原因,我们是由
模板代码如下,似乎与前面别无二致:
1 2 3 4 5 6 7 8 9 10 for (int i = 1 ; i <= n; i ++) { for (int j = m; j >= 0 ; j --) { if (j > w[i]) f[j] = max (f[j], f[j - w[i]] + v[i]); else f[j] = f[j]; } }
我们
采药
山洞里有不同的草药,采摘每一株都需要不同的时间,每一株都有其自身的价值,每种草药只能采摘一次,问能在给定时间内能采到草药最大的价值。
因为是
1 2 3 4 5 6 7 for (int i = 1 ; i <= n; i ++) { for (int j = m; j >= w[i]; j --) { f[j] = max (f[j], f[j - w[i]] + v[i]); } }
常数优化 当我们在枚举空间时,有如下优化:
1 for (int j = m; j >= max (m - (sumw[n] - sumw[i]), v[i]));
其中
大概意思是当
bitset 优化 这个优化通常是用于那些需要涉及集合的题目的,但是不学又不行,我也不想学呀,有什么办法呢。
这里废话我们不讲,
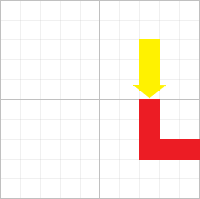
完全背包 这是最简单的动态规划问题。
似乎这个问题非常の不切实际的,问题建立在什么物品都能无限拿(所谓“完全”)的环境中,在不超过空间的前提下,问最大的贡献。
那么策略就不是单纯地拿或者不拿了,进化到了拿
如果此时
模板代码如下:
1 2 3 4 5 6 7 8 9 10 for (int i = 1 ; i <= n; i ++) { for (int j = m; j >= 0 ; j --) { for (int k = 0 ; k * w[i] <= j; k ++) { f[i][j] = max (f[i][j], f[i - 1 ][j - k * c[i]] + k * val[i]); } } }
当然也可以写成这样(同时优化了空间):
1 2 3 4 5 6 7 8 9 10 for (int i = 1 ; i <= n; i ++) { for (int j = m; j >= 0 ; j --) { for (int k = 0 ; k * w[i] <= j; k ++) { f[j] = max (f[j], f[j - k * c[i]] + k * val[i]); } } }
在这段代码里,如果这个物品的重量 正序循环 的原因。
求解一个状态
这里给出一个《采药》的进阶版例题:
疯狂的采药
山洞里有不同的草药,采摘每一株都需要不同的时间,每一株都有其自身的价值,每种草药能采摘无限次,问能在给定时间内能采到草药最大的价值。
可以直接交一发模板代码(要开
1 2 3 4 5 6 7 for (int i = 1 ; i <= n; i ++) { for (int j = w[i]; j <= m; j ++) { f[j] = max (f[j], f[j - w[i]] + val[i]); } }
优化 这里可以想到一个简单有效的优化,若两件物品
转化 世界线收束。,我们可以把完全背包转为
显然,在完全背包中,第
更高效的还可以采用二进制思想,把第
时间优化 上联:前面的复杂度很大,我们还是要来优化。
下联:如果你觉得这个算法很差,请你来
横批:代码如下。
1 2 3 4 5 6 7 for (int i = 1 ; i <= n; i ++) { for (int j = w[i]; j <= m; j ++) { f[j] = max (f[j], f[j - w[i]] + val[i]); } }
观察,这份代码和
绝无已经选入 第 每件物品只选一次 。而现在每种物品能选无限件,考虑“选入第 可能已选入子结果
时间复杂度是
多重背包 这是最简单的动态规划问题。
这是一个比
现在对于每个物品有
根据前面的经验,我们只要偷个懒把前面的方程改一下就可以了,现在方程是这样的:
复杂度是
转化 世界线再次收束。
和前面转化的思想一样,把第
时间复杂度仍没有改变,还是
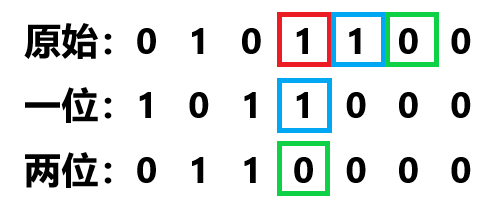
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 for (int i = 1 ; i <= n; i ++) { int x = 1 ; while (s[i] >= x) { s[i] -= x; g[++ cnt].w = x * w[i]; g[cnt].v = val[i] * x; x <<= 1 ; } if (s[i] > 0 ) { g[++ cnt].w = s[i] * w[i]; g[cnt].v = val[i] * s[i]; } }
第一个问题 ,对于这段代码:
对于一个被“解剖”的物品部分将其看做一坨东西,假设现在有
那么我们将其二进制化以后,还留下来一个
比如说上面那张图,第二个块就是一个价值为
分组背包 这是最简单的动态规划问题。
这是一个还算比较真实的问题,但是没有多重背包真实,而且你甚至能把它代到游戏等环境中?
对于所有背包,将其分成
比较朴素的想法是,遍历共
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 for (int i = 1 ; i <= k; i ++) { for (int j = m; j >= 0 ; j --) { for (int l = 1 ; l <= s[i]; l ++) { int x = a[i][l]; if (j >= w[x]) { f[j] = max (f[j], f[j - w[x]] + val[x]); } } } }
三层循环的顺序保证了每一组内的物品最多只有一个被加入到背包中。
二维费用背包 这是最简单的动态规划问题。
前面我们可能活在一个牛顿不在的世界,物品竟然是没有体积只有质量的,难以置信。
现在的物品多了一个属性,即容积,二维费用背包问题就是给定背包的最大容积
既然换了个世界,就要多加一维,那么状态也多加一维,状态转移方程如下:
当每件物品只能取一次时,让体积和容量采用逆序的循环,完全背包时采用顺序的循环,多重背包时拆分物品。
1 2 3 4 5 6 7 8 9 10 for (int i = 1 ; i <= n; i ++) { for (int j = W; j >= 0 ; j --) { for (int k = V; k >= 0 ; k --) { f[j][k] = max (f[j][k], f[j - w[i]][k - v[i]] + val[i]); } } }
依赖背包 这是最简单的动态规划问题。
这种背包问题的存在是因为某些病毒软件,下了这个又要给你下它本家的所有东西,它本家的东西又要给你下别的病毒软件的东西。
问题中的物品间存在某些“依赖”关系。也就是说物品
考虑到所有策略都是互斥的(也就是只能选择一种策略),所以一个主件和它的附件可以被看做一个分组背包中的一组。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 for (int i = 1 ; i <= k; i ++) { for (int j = m; j >= 0 ; j --) { for (int l = 1 ; l <= s[i]; l ++) { int x = a[i][l]; if (j >= w[x]) { f[j] = max (f[j], f[j - w[x]] + val[x]); } } } }
当然对于一些选择策略比较少的题目(如《金明的预算方案》,也可以考虑使用
有一部分依赖背包的多种决策是在取完前一种才能取的,同样也给了我们另一个思路来存组内决策,如这题:
黄金矿工
边缘正在玩黄金矿工,现在他想要在时间
这里可以用到笛卡尔坐标系来算斜率判哪些黄金在同一条线上,同时使用排序降低难度,将其放进一组,然后因为对于一条线上的黄金(一组里的)拿后面那个黄金的前提是拿前面的黄金(体现其依赖性),所以它的价值就是加上它的价值,花费亦是如此,然后简单跑一个分组背包应该不是问题,完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> using namespace std ;const int N = 2e3 + 1 ;int n, t, cnt;int s[N], v[N][N], ti[N][N], f[40001 ];struct Gold { int x, y, t, val; double k; } a[N]; inline bool cmp (Gold p, Gold q) return p.k == q.k ? p.y < q.y : p.k < q.k; } int main () scanf ("%d %d" , &n, &t); for (int i = 1 ; i <= n; i ++) { scanf ("%d %d %d %d" , &a[i].x, &a[i].y, &a[i].t, &a[i].val); a[i].k = a[i].y * 1.0 / (a[i].x * 1.0 ); } sort (a + 1 , a + n + 1 , cmp); for (int i = 1 ; i <= n; i ++) { if (a[i].k != a[i - 1 ].k || i == 1 ) ++ cnt; if (!s[cnt]) { v[cnt][++ s[cnt]] = a[i].val; ti[cnt][s[cnt]] = a[i].t; } else { ++ s[cnt]; v[cnt][s[cnt]] = v[cnt][s[cnt] - 1 ] + a[i].val; ti[cnt][s[cnt]] = ti[cnt][s[cnt] - 1 ] + a[i].t; } } for (int i = 1 ; i <= cnt; i ++) for (int j = t; j >= 0 ; j --) { int maxn = f[j]; for (int k = 1 ; k <= s[i]; k ++) if (j >= ti[i][k]) maxn = max (maxn, f[j - ti[i][k]] + v[i][k]); f[j] = maxn; } printf ("%d" , f[t]); }
泛化物品 这是……啊,不对,这好像不是动态规划问题啊……
考虑这样一种物品,它并没有固定的费用和价值 ,而是它的价值随着你分配给它的费用而变化。
更严格的定义。在背包容量为
一个费用为
如果给定了两个泛化物品
因为这里的
到达背包 这是最简单的动态规划问题。
对于一种是否能完成一个任务的题目,令
这里给出例题:
音量调节
一个吉他手决定参加一场表演,每表演一首歌前他必须改变一次音量,可以是降低或升高,最低不可以低于
这题不可以使用滚动数组,其他就等于是模板吧,只是状态里存的是现在是否可行就是了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <bits/stdc++.h> using namespace std ;int n, maxn, x; int a[51 ], f[51 ][1001 ];int main () scanf ("%d %d %d" , &n, &x, &maxn); f[0 ][x] = 1 ; for (int i = 1 ; i <= n; i ++) scanf ("%d" , &a[i]); for (int i = 1 ; i <= n; i ++) { for (int j = maxn; j >= 0 ; j --) { if (j - a[i] >= 0 ) f[i][j] = f[i][j] || f[i - 1 ][j - a[i]]; if (j + a[i] >= 0 ) f[i][j] = f[i][j] || f[i - 1 ][j + a[i]]; } } for (int i = maxn; i >= 1 ; i --) if (f[n][i]) return cout << i, 0 ; return cout << -1 , 0 ; }
进程背包 这是最简单的动态规划问题。
对于这种加工调换过程的
产品加工
某加工厂有
特别的,当一个时间为
开始先设计状态,
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <bits/stdc++.h> using namespace std ;int n, m, ans = 0x7fffffff , down, up, f[30001 ];inline int max (int x, int y) return x > y ? x : y; } inline int min (int x, int y) return x < y ? x : y; } int main () scanf ("%d" , &n); for (register int i = 1 ; i <= n; i ++) { int a, b, c; scanf ("%d %d %d" , &a, &b, &c); m = down; down = 0x7fffffff ; up += max (a, max (b, c)); for (register int j = up; j >= m; j --) { int tmp = 0x7fffffff ; if (a && j - a >= m) tmp = min (tmp, f[j - a]); if (b) tmp = min (tmp, f[j] + b); if (c && j - c >= m) tmp = min (tmp, f[j - c] + c); if (tmp < 0x7fffffff ) down = min (down, j); f[j] = tmp; } } for (int i = down; i <= up; i ++) ans = min (ans, max (i, f[i])); printf ("%d\n" , ans); return 0 ; }
分数规划背包 这是最简单的动态规划问题。
写到下面例题的时候突然遇到了,所以跑上来补一下。
分数规划问题 首先随便讲讲分数规划问题。
对于一个集合
然后这种问题使用的通常是二分法或者
啊还有什么各种模型比如最优比率树啦,最优比率环啦,最大密度子图啦,这种东西都不重要的晓得哇,天塌下来我都不会去学。
例题
阿米娅的儿童节礼物
可露希尔的商店里有
博士希望礼物的心意值恰好是价值的
先拆柿子:
所以我们就可以使用分数规划的老套路:
再以
需要注意的是,由于
给出代码~当当了当:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <bits/stdc++.h> using namespace std ;const int N = 2e4 + 1 ;int n, k, f[N], g[N];int a[N], b[N], c[N], ans;int main () scanf ("%d %d" , &n, &k); for (int i = 1 ; i <= 1e4 + 1 ; i ++) f[i] = g[i] = -1e9 ; for (int i = 1 ; i <= n; i ++) scanf ("%d" , &a[i]); for (int i = 1 ; i <= n; i ++) scanf ("%d" , &b[i]); for (int i = 1 ; i <= n; i ++) { c[i] = a[i] - b[i] * k; if (c[i] >= 0 ) for (int j = 1e4 ; j >= c[i]; j --) f[j] = max (f[j], f[j - c[i]] + a[i]); else for (int j = 1e4 ; j >= -c[i]; j --) g[j] = max (g[j], g[j + c[i]] + a[i]); } for (int i = 0 ; i <= 1e4 ; i ++) ans = max (ans, f[i] + g[i]); if (ans > 0 ) printf ("%d\n" , ans); else puts ("-1" ); return 0 ; }
时间排序背包 这是最简单的动态规划问题。
自己起的名字,其实只是一个
抢救物资
有人的房子着火了,他想从大火中带走价值总和尽量多的物品,每次他只能带走一个,分别给出挽救某物品需要的时间,该物品开始燃烧的时间(从该时间开始就不能挽救该物品了),物品的价值。
非常的,你可以看出这是一个背包问题对吧,而且似乎只是把时间用做了背包空间。
但是在此之前先让我们给物品按照开始燃烧的时间排序,这样才能满足无后效性。
然后就按照正常背包做吧,代码给出:
1 2 3 4 5 6 7 8 for (int i = 1 ; i <= n; i ++) for (int j = a[i].d - 1 ; j >= a[i].t; j --) if (f[j - a[i].t] + a[i].val > f[j]) { f[j] = f[j - a[i].t] + a[i].val; res[j] = res[j - a[i].t]; res[j].push_back (a[i].id); }
区间动态规划 这是最简单的动态规划问题。
区间 线性动态规划 的拓展,它在分阶段地划分问题时,与阶段中元素出现的顺序和由前一阶段的哪些元素合并而来有很大的关系,那么既然是在区间上,我们可以随便设一个最基础的状态
对于一个区间中,比较常规的想法是将其分成
其中
先从一道简单的题目入手:
石子合并
在一个环上摆放
看到环,首先断环成链得到一个两倍的数组,再令
这里可以采用前缀和预处理出区间
1 2 3 4 5 6 7 8 9 10 11 12 for (int i = 1 ; i <= n; i ++) { for (int j = 1 ; i + j <= 2 * n; j ++) { int end = i + j - 1 ; for (int k = j; k < end; k ++) { f1[j][end] = min (f1[j][end], f1[j][k] + f1[k + 1 ][end] + sum[end] - sum[j - 1 ]); f2[j][end] = max (f2[j][end], f2[j][k] + f2[k + 1 ][end] + sum[end] - sum[j - 1 ]); } } }
此时的时间复杂度是
当然对于一些回文字符串的题目,区间
天王老子来我都不学马拉车
给定一个由小写字母组成的字符串
时间给的老长了,
然后可以确定状态是 中心扩散法 ,也就是弄两个指针往外判是不是回文串。
然后为了方便理解我们来把样例”
然后你可能会觉得似乎是有点规律的但其实好像是没有规律的(我在说什么我靠)。
回文子串是有奇数和偶数长度两种情况,所以两种都要算。
给出代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <bits/stdc++.h> using namespace std ;const int N = 5e3 + 1 ;char s[N];int f[N][N], n, q;int main () scanf ("%s" , s + 1 ); scanf ("%d" , &q); n = strlen (s + 1 ); for (int i = 1 ; i <= n; i ++) { for (int j = i, k = i; j && k <= n && s[j] == s[k]; j --, k ++) f[j][k] ++; for (int j = i, k = i + 1 ; j && k <= n && s[j] == s[k]; j --, k ++) f[j][k] ++; } for (int i = 1 ; i <= n; i ++) for (int j = 1 ; j <= n; j ++) f[i][j] += f[i][j - 1 ] + f[i - 1 ][j] - f[i - 1 ][j - 1 ]; for (int l, r; q --;) { scanf ("%d %d" , &l, &r); printf ("%d\n" , f[r][r] - f[l - 1 ][r] - f[r][l - 1 ] + f[l - 1 ][l - 1 ]); } return 0 ; }
诶你可能会说上面这个题目不够回文串,那我再来一道回文串题目:
祖玛游戏
祖玛游戏里,存在
(其实原祖玛只要三颗珠子连在一起了就会自己消掉)
呃……这个其实就是推
然后可以想到,对于一个珠子,代价就是
对于相邻的珠子,如果它们俩相同,代价就是
那么初始化就是这样,然后我们去一步步弄出大区间,那么对于一个宝石串而言,如果两端相同,代价和加不加这两端是一样的,所以可以由前面那个推出来,即
然后记得套区间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <bits/stdc++.h> using namespace std ;const int N = 501 ;const int inf = 20050409 ; int n, a[N], f[N][N];int main () scanf ("%d" , &n); for (int i = 1 ; i <= n; i ++) scanf ("%d" , &a[i]); for (int i = 1 ; i <= n; i ++) for (int j = 1 ; j <= n; j ++) f[i][j] = inf; for (int i = 1 ; i <= n; i ++) f[i][i] = 1 ; for (int i = 1 ; i < n; i ++) { if (a[i] == a[i + 1 ]) f[i][i + 1 ] = 1 ; else f[i][i + 1 ] = 2 ; } for (int i = 3 ; i <= n; i ++) { for (int j = 1 ; i + j - 1 <= n; j ++) { int l = j, r = i + j - 1 ; if (a[l] == a[r]) f[l][r] = f[l + 1 ][r - 1 ]; for (int k = l; k < r; k ++) f[l][r] = min (f[l][r], f[l][k] + f[k + 1 ][r]); } } printf ("%d" , f[1 ][n]); return 0 ; }
树形动态规划 由于树固有的递归性质,树形动态规划一般都是递归进行的。
一般来说树形
基础 这是……额……反正有例题!那就是最简单的动态规划问题了!
我们从一道老生常谈的题开始,《没有上司的舞会》:
没有上司的舞会
某大学有
可以定义
显然,我们可以推出两个状态转移方程:
第一个方程,对于上司
第二个方程,对于上司
通过
1 2 3 4 5 6 7 8 9 10 11 12 13 void dfs (int p) vis[p] = 1 ; for (int i = head[p]; i; i = edge[i].nxt) { if (vis[edge[i].to]) continue ; dfs (edge[i].to); f[p][1 ] += f[edge[i].to][0 ]; f[p][0 ] += max (f[edge[i].to][0 ], f[edge[i].to][1 ]); } return ; }
还有一道处理方法更普遍的题目,《二叉苹果树》
二叉苹果树
有一棵苹果树,树枝必分为两叉,这棵树共有
对于每个父节点的状态都是由它的子节点转移过来的,父节点上选择的边数完全取决于子节点的子树选择的边数。
令
第一种策略,取以
第二种策略就是不取,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void dfs (int p, int fath) for (int i = head[p]; il i = edge[i].nxt) { int v = edge[i].to; if (v == fath) continue ; dfs (v, p); size[p] += size[v] + 1 ; for (int j = min (m, size[p]); j; j --) for (int k = min (j - 1 , size[v]); k >= 0 ; k --) f[p][j] = max (f[p][j], f[p][j - k - 1 ] + f[v][k] + edge[i].w); } }
对于取最小值,大概就是瓶颈边(网络流里的叫法),一般来说是
树上背包 这是最简单的动态规划问题。
树上背包问题,本质上是分组背包,比较经典的是《有线电视网》和《选课》。
选课
现在有
一位学生现在要学习
每门课只有一门先修课的特点,与有根树里的父子关系相似。
因为有可能有一坨没有先修课的课程,所以形成了一坨森林,这个时候就可以增加一门编号为
那么可以令
转移的过程结合了树形
记点
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void dfs (int p) for (int i = head[p]; ~i; i = edge[i].nxt) { int v = edge[i].to; dfs (v); for (int j = m + 1 ; j > 0 ; j ++) { for (int k = 0 ; k < j; k ++) { f[p][j] = max (f[p][j], f[p][j - k] + f[v][k]); } } } }
有线电视网
某收费有线电视网计划转播一场重要的足球比赛。他们的转播网和用户终端构成一棵树状结构,这棵树的根结点位于足球比赛的现场,树叶为各个用户终端,其他中转站为该树的内部节点。
从转播站到转播站以及从转播站到所有用户终端的信号传输费用都是已知的,一场转播的总费用等于传输信号的费用总和。
现在每个用户都准备了一笔费用想观看这场精彩的足球比赛,有线电视网有权决定给哪些用户提供信号而不给哪些用户提供信号。
找出一个方案使得有线电视网在不亏本的情况下使观看转播的用户尽可能多。
实则也是就是个分组背包,换汤不换药。
对于这道题,有了前面的经验,状态和方程就更好推了,设
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int dfs (int u) if (u > n - m) { dp[u][1 ] = val[u]; return 1 ; } int res = 0 ; for (int i = head[u]; i; i = edge[i].nxt) { int v = edge[i].to; t = dfs (v); sum += t; for (int j = sum; j >= 0 ; j --) for (int k = 1 ; i <= t; k ++) if (j - k >= 0 ) f[u][j] = max (f[u][j], f[u][j - k] + f[v][k] - edge[i].w) } return sum; }
换根动态规划 这是最简单的动态规划问题。
当然有的时候问题需要的根是不定的,当然意思不是这个根会飘来飘去。
那我们最后来一道脚造例题好了:
移动城邦
泰拉大陆上的某个国家一共有
对于每个点都可以被当做根的这种问题,很显然,如果我们用
那其实就有一个很好的想法,从一个点转移到它的子节点,其贡献改变为其上面集体加这个点到子节点的距离和下面集体减这个点到子节点的距离,然后每个点的贡献直接通过公式转移就可以了。上面节点数就是
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 #include <bits/stdc++.h> #define int long long using namespace std ;const int N = 4e5 + 1 ;int n;struct Edge { int nxt, to; } edge[N]; int head[N], cnt;int dis[N], siz[N], a[N], maxn, ans; inline void add_edge (int u, int v) edge[++ cnt].to = v; edge[cnt].nxt = head[u]; head[u] = cnt; } priority_queue <pair <int , int > > Q;bool vis[N];void dijkstra (int s) memset (dis, 0x3f , sizeof dis); dis[s] = 0 ; Q.push (make_pair (0 , s)); while (!Q.empty ()) { int x = Q.top ().second; Q.pop (); if (vis[x]) continue ; vis[x] = 1 ; for (int i = head[x]; i; i = edge[i].nxt) { int v = edge[i].to; if (dis[v] > dis[x] + 1 ) { dis[v] = dis[x] + 1 ; Q.push (make_pair (-dis[v], v)); } } } } void dfs1 (int u, int fath) siz[u] = 1 ; for (int i = head[u]; i; i = edge[i].nxt) { int v = edge[i].to; if (v == fath) continue ; dfs1 (v, x); siz[u] += siz[v]; } } void dfs2 (int u, int fath) for (int i = head[u]; i; i = edge[i].nxt) { int q = edge[i].to; if (q == fath) continue ; a[q] = n + a[u] - 2 * siz[q]; dfs2 (q, u); } } signed main () int u, v; scanf ("%d" , &n); for (int i = 1 ; i < n; i ++) { scanf ("%lld %lld" , &u, &v); add_edge (u, v); add_edge (v, u); } dijkstra (1 ); for (int i = 1 ; i <= n; i ++) a[1 ] += dis[i]; dfs1 (1 , 0 ); dfs2 (1 , 0 ); for (int i = 1 ; i <= n; i ++) if (a[i] > maxn) ans = i, maxn = a[i]; printf ("%lld" , ans); }
边缘要赢到巨多例题!
基环树动态规划 这是最简单的动态规划问题。
基环树也叫环套树。
基环树听着很高大上,但是其实只不过是一个有 只有一个环并且删掉环上任意一条边都可以变成一棵树 。
好像一个水母。
然后我们从一道例题开始讲这个(其实只有一道例题)。
卡西米尔骑士团
卡西米尔有很多骑士,比如锋盔骑士啦,呼啸骑士啦,左手骑士啦,杂七杂八的。
现在要组织一场比赛,有几个志同道合的骑士要组成一个骑士团打比赛。
但是有些骑士之间是有矛盾的,一个骑士不会和与自己有矛盾的人在同一个骑士团,现在要博士你组织一个骑士团去打比赛,使得这个骑士团内不出现有矛盾的两人(不存在骑士和与他痛恨的人一同被选入骑士团的情况),并且使得这个骑士团有战斗力,一个骑士团的战斗力为所有骑士的战斗力总和。
首先这个题目非常像《没有上司的舞会》。
虽然说里面有个环,但是我们可以将其拆开,然后从被拆开那条边的两个端点各自开始进行树形
看一下完整代码,注释应该很详细了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 #include <bits/stdc++.h> #define int long long using namespace std ;const int N = 1e6 + 1 ;int n, m, a[N];struct Edge { int nxt, to; } edge[N << 1 ]; int head[N], cnt = -1 ; int f[N][2 ], ans, maxn; int root1, root2, cut; bool vis[N], cir[N];inline void add_edge (int u, int v) edge[++ cnt] = (Edge) {head[u], v}; head[u] = cnt; } void find_circle (int p, int pre) vis[p] = cir[p] = 1 ; for (int i = head[p]; i; i = edge[i].nxt) { int v = edge[i].to; if (cir[v] && i != (pre ^ 1 )) { root1 = p; root2 = v; cut = i; } if (!vis[v]) find_circle (v, i); } cir[p] = 0 ; } void dfs (int p, int pre) f[p][0 ] = f[p][1 ] = 0 ; for (int i = head[p]; i; i = edge[i].nxt) { int v = edge[i].to; if (v == pre || i == cut || i == (cut ^ 1 )) continue ; dfs (v, p); f[p][1 ] += f[v][0 ]; f[p][0 ] += max (f[v][1 ], f[v][0 ]); } f[p][1 ] += a[p]; } signed main () scanf ("%lld" , &n); for (int i = 1 , x; i <= n; i ++) { scanf ("%lld %lld" , &a[i], &x); add_edge (i, x); add_edge (x, i); } for (int i = 1 ; i <= n; i ++) if (!vis[i]) { maxn = 0 ; find_circle (i, -1 ); dfs (root1, 0 ); maxn = max (f[root1][0 ], maxn); dfs (root2, 0 ); maxn = max (f[root2][0 ], maxn); ans += maxn; } return printf ("%lld" , ans) & 0 ; }
状态压缩动态规划 这是最简单的动态规划问题。
状压 计算机二进制 的性质来描述状态来达到优化转移 的一种
:始开目题的谈常生老个一从们我让
炮兵阵地
司令部的将军们在
在每一个平原地形上最多可以部署一支炮兵部队,一支炮兵部队的攻击范围是这样的:
现在,将军们该如何部署炮兵部队,在防止误伤的情况下,最多能摆放多少支炮兵部队。
现在有一个很好的想法,我可以利用一个
如果这是其中一行的状况,可以将其表示为一个整数,也就是把这个
我们就可以令
对于左右呢,我们要请出位运算 !
对于这样一行状态,考虑到可以使用位运算 & ,即“与”,存在
那么我们就可以对这个串进行左移 << 和右移 >> ,来简单地判断左右放的炮兵是否冲突,左移一位(判断右边)是否效果如下:
然后对比这一列发现右边有一个是冲突的(好吧这是显而易见的),右移就是对比左边的。
判断上下的时候就很简单,直接比对这两行有无冲突就好了:
转移方程就是如果满足这两个前提就加上这一排最多能放的就是了:
也许完整的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <bits/stdc++.h> using namespace std ;int n, m, F[105 ], f[105 ][66 ][66 ], start[70 ], cnt = 0 , val[200 ];bool mp[105 ][30 ];int main () char ch; scanf ("%d %d" , &n, &m); for (int i = 1 ; i <= n; i ++) for (int j = 1 ; j <= m; j ++) { cin >> ch; if (ch == 'H' ) mp[i][j] = 1 ; } for (int i = 1 ; i <= n; i ++) for (int j = 1 ; j <= m; j ++) F[i] = (F[i] << 1 ) + mp[i][j]; start[++ cnt] = 0 ; for (int i = 1 ; i < (1 << m); i ++) { if (i & (i << 1 )) continue ; if (i & (i << 2 )) continue ; if (i & (i >> 1 )) continue ; if (i & (i >> 2 )) continue ; start[++ cnt] = i; int x = i; while (x) { val[cnt] ++; x -= (x & (-x)); } } for (int i = 1 ; i <= cnt; i ++) if ((start[i] & F[1 ]) == 0 ) f[1 ][i][0 ] = val[i]; for (int i = 1 ; i <= cnt; i ++) if ((start[i] & F[2 ]) == 0 ) for (int j = 1 ; j <= cnt; j ++) if ((start[i] & start[j]) == 0 && (start[j] & F[1 ]) == 0 ) f[2 ][i][j] = val[i] + val[j]; for (int i = 3 ; i <= n; i ++) for (int j = 1 ; j <= cnt; j ++) if ((start[j] & F[i]) == 0 ) for (int k1 = 1 ; k1 <= cnt; k1 ++) if ((start[j] & start[k1]) == 0 && (start[k1] & F[i - 1 ]) == 0 ) for (int k2 = 1 ; k2 <= cnt; k2 ++) if ((start[j] & start[k2]) == 0 && (start[k1] & start[k2]) == 0 && (start[k2] & F[i - 2 ])==0 ) f[i][j][k1] = max (f[i][j][k1], f[i - 1 ][k1][k2] + val[j]); int ans = 0 ; for (int i = 1 ; i <= cnt; i ++) for (int j = 1 ; j <= cnt; j ++) ans = max (ans, f[n][i][j]); return cout << ans, 0 ; }
对于一坨题目,推荐这个博客:偷学笔记 ,讲的非常多,非常棒!
数位动态规划 这是最简单的动态规划问题。
数位
1 2 3 4 5 6 7 8 9 10 11 12 13 bool f (int x) cnt = 0 ; while (x) { a[cnt ++] = x % 10 ; x /= 10 ; } reverse (a, a + cnt); } for (int i = l; i <= r; i ++) if (f (i) == true ) ans ++;
但是这样时间复杂度是
数位 记忆化搜索 的方式来实现。例如我们要求
让我们用一道早死偶缄的的题目开始:
数字计数
给定两个正整数
数位 合并相同状态 ,有些答案是一样的,那么就可以当做相同的状态,当枚举到的时候发现这种状态的答案已经被记录过了,于是可以直接返回。
还有一个很有意思的新东西就是
如果此时是百位是
因为这个时候十位的数不能大于百位的数(好像是句废话?):
但是如果此时百位的数是
至于前导零,看运气,看你遇到的啥题目,面对题目编程。
一般来说的话,前面位数枚举零就算作是枚举位数比原数少的数。
然后采用前缀和思想算
1 printf ("%d" , f (r) - f (l - 1 ));
完整代码如下(缝合拼接怪,我把两份完全不一样的代码拼到了一起):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <bits/stdc++.h> #define int long long using namespace std ;int A[21 ], cnt, digit, f[22 ][22 ][2 ][2 ];int dfs (int pos, int cntd, bool limit, bool lead) int ans = 0 ; if (pos == 0 ) return cntd; if (f[pos][cntd][limit][lead] != -1 ) return f[pos][cntd][limit][lead]; for (int v = 0 ; v <= (limit ? A[pos] : 9 ); v ++) if (lead && v == 0 ) ans += dfs (pos - 1 , cntd, limit && v == A[pos], true ); else ans += dfs (pos - 1 , cntd + (v == digit), limit && v == A[pos], false ); f[pos][cntd][limit][lead] = ans; return ans; } int calc (int x) cnt = 0 ; memset (f, -1 , sizeof (f)); memset (A, 0 , sizeof (A)); while (x) { A[++ cnt] = x % 10 ; x /= 10 ; } return dfs (cnt, 0 , true , true ); } signed main () int a, b; scanf ("%lld %lld" , &a, &b); for (int i = 0 ; i < 10 ; i ++) { digit = i; printf ("%lld " , calc (b) - calc (a - 1 )); } return 0 ; }
期望动态规划 数学期望 这是最简单的……这好像也不是动态规划问题啊……
对于一组离散型变量 ,出现其中某一变量的概率乘以这一变量值,求和,就是数学期望 ,如下:
所谓期望,其实表示的是一组离散型随机变量的平均水平,也就是进行某件事能得到的平均结果,或理想代价。
就好像我买
也好像我打
期望DP 这是最简单的动态规划问题。
对于一种很难找到递推关系的数学期望问题,就可以利用期望的定义式,根据实际情况,以概率或方案数(或它们的乘积)表示一种状态,一般来说还是用
求我现在会用老生常谈的题目开始的期望:
麻球繁衍
一开始有
首先,可以想到,如果中一张彩票概率是
那么以此类推,考虑一只麻球在
考虑一只麻球,结合全概率公式,
那么答案就是
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std ;const int N = 1e3 + 1 ;int k, n, m, t;double p[N], f[N];int main () scanf ("%d" , &t); for (int tt = 1 ; tt <= t; tt ++) { memset (f, 0 , sizeof (f)); memset (p, 0 , sizeof (p)); scanf ("%d %d %d" , &n, &k, &m); for (int i = 0 ; i < n; i ++) scanf ("%lf" , &p[i]); f[1 ] = p[0 ]; f[0 ] = 0 ; for (int i = 2 ; i <= m; i ++) { f[i] = 0 ; for (int j = 0 ; j < n; j ++) f[i] += p[j] * pow (f[i - 1 ], j); } printf ("Case #%d: %.7lf\n" , tt, pow (f[m], k)); } return 0 ; }
原题题目名是 四叶草 ,而且麻球好像是一种吃的……不是小鸟吧……(不是很懂为什么叫麻球 www )
插头动态规划 这是最简单的动态规划问题。
插播一个喜报 :前一天准备要写的时候我在听相声《华容道》,然后这个时候临近晚自修下课了,突然
然后我还在宿舍里和他说,你就不能把蟑螂看做
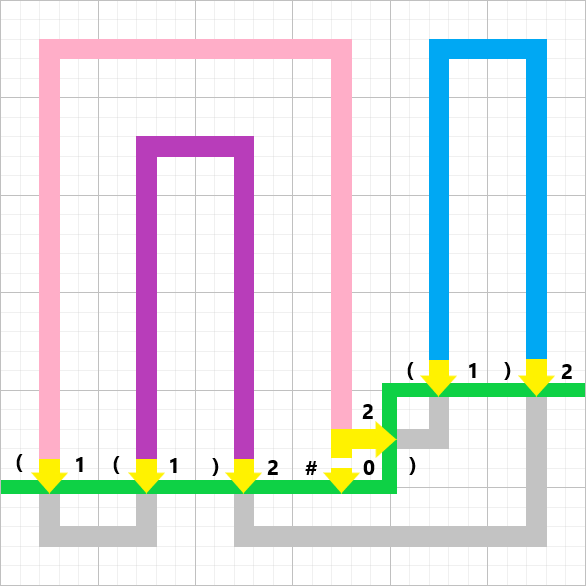
插头动态规划问题是一种基于连通性的动态规划问题,我们从一道 $** $ 的题来讲:
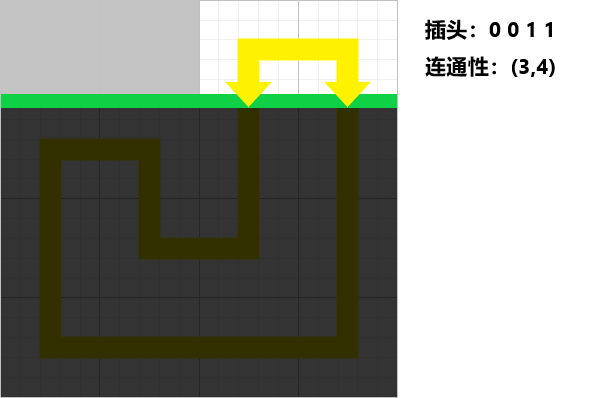
插头
给出
其实应该叫轮廓线动态规划 ,这个之后会讲,反正我知道大家肯定都懂了(悲)。
那还是来给个例子,比如以下的情况:
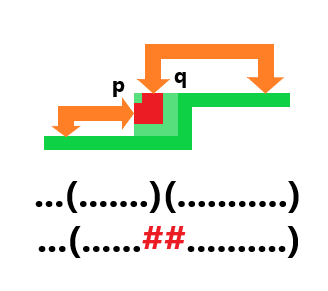
插头 对于一个四连通的问题来说,它通常有上下左右四个插头,一个方向的插头存在表示这个格子在这个方向可以与外面相连。
可以发现所有的非障碍格子一定是从一个格子进来,另一个格子出去,即四个插头恰好有两个插头存在,共六种情况。
然后那么存在六种情况:
然后我们要做的就是用这些“拼图”形成一个回路,就很像接水管游戏。
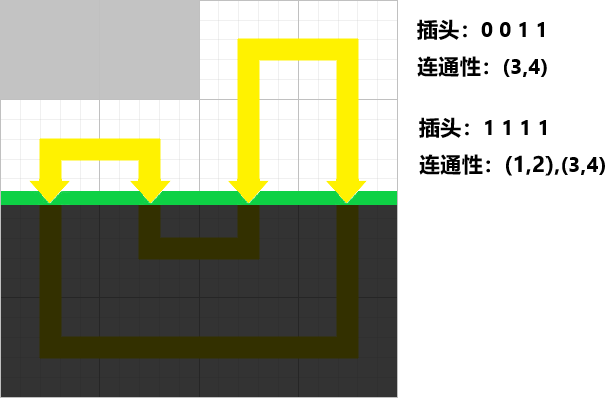
轮廓线 相信大家都听说过,轮廓线 就是当前决策的边界 ,即已决策鸽子和未决策鸽子的界线:
轮廓线上方与其相连的最多有
还有一种是逐行递推,从上到下的顺序依次考虑每行:
状态 逐行递推的状态 不妨按照从上到下的顺序依次考虑每一行,分析第
我们需要记录第
但是仅仅记录插头是否存在是不够的,可能导致出现多个回路,而本题仅要求一个回路。
也就隐含着最后所有的非障碍格子通过插头连接成了一个连通块 ,因此还要记录第
那么让我们来模拟一下:
因为左边的两个格子是障碍,所以没有下插头,第
四个格子都有下插头,第
中间的两格不存在下插头,这四格通过弯弯曲曲的回路相连。
通过上面的分析,可以写出动态规划的状态。用
关于连通性,我们通常给每一个格子标记一个正数,属于同一个的连通块的格子标记相同的数,比如 最小表示法 。
最小表示法 为所有的障碍格子标记为
比如连通信息
我们就可以拿出之前的那个例子来试手。
对于第一行,前两格因为是障碍所以是
对于第二行,全都有下插头,前两格相连,后两格相连
对于第三行,前后两格有下插头,中间四格全都相连,属于一个连通块:
插播一个喜报 :夏天晚霞超级好看!!!
通过观察发现如果轮廓线上方的
比如之前的第三行的状态:
就可以表示为:
同理,第二行的是这样的:
逐格递推的状态 因为逐行递推很慢,所以要来讲逐格递推。
从左到右依次给
当然也可以类似优化,格子的连通性记录在插头上,状态变为
来做个模拟!给一些大家肯定都看到过的图(哦我之前放过了,那比较尴尬)。
对于第一格,有一个存在的下插头和一个不存在的右插头。
所以此时的状态为:
对于第二格,有一个存在的右插头和一个不存在的下插头,然后左右的连通块不相连:
所以此时状态为:
对于第三格,有一个不存在的下插头和一个不存在右插头,然后两边全部连通:
所以此时状态为:
简单的回路问题 对于简单的回路问题,我们可以找出两个特点。
插头两两匹配 ,可以从下面这张图发现这个特点:
可以发现轮廓线上方是由若干条互不相交 的路径构成的,而每条路径的两个端口恰好对应了轮廓线上的两个插头。
一条路径上的所有格子对应的是一个连通块,而每条路径的两个端口对应的插头是连通的,而且不与其他任何一个插头连通。
插头不会交叉 ,设现在轮廓线上从左到右四个插头
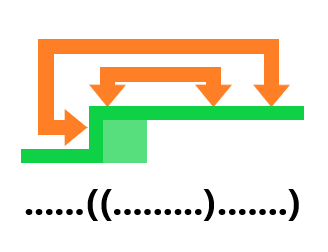
由此我们可以找出存储插头状态的方法,就是括号序列 。
括号表示法 我们可以用这种法则来表示插头连通性:
给出上面那个图的例子:
那么可以写成:
用三进制表示为:
可能图会比较糊,但是我们要讲接下来的了。
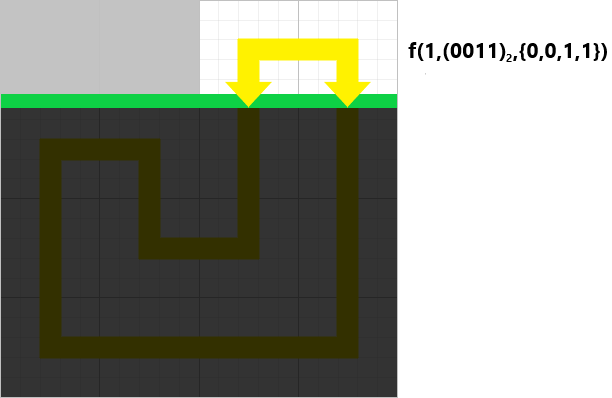
转移状态 逐行递推 假设从第
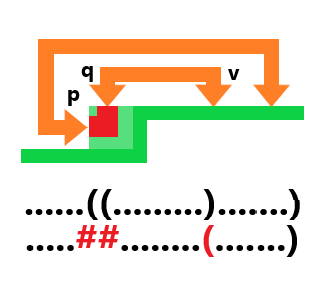
对于左边和上边有插头的情况,格子的状态是一定确定的:
然后对于上面有插头的情况,有两种情况,第一种是直下:
还有一种是向右弯:
至于这里为什么没有向左弯,是因为必须存在两个插头才可以确定,因为你是从左边推过来的,如果是左边那一格的没有插头呢,对吧,一定要保证左边的是右插头才能确定这一格的状态为向右弯。
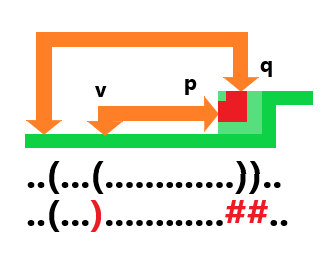
然后对于左边有插头的情况,也有两种情况,第一种是直左:
同上面,还有一种是向下弯,理由前面说过了,这里不再赘述:
最后一种情况是肯定的,因为这是在没有插头的情况下:
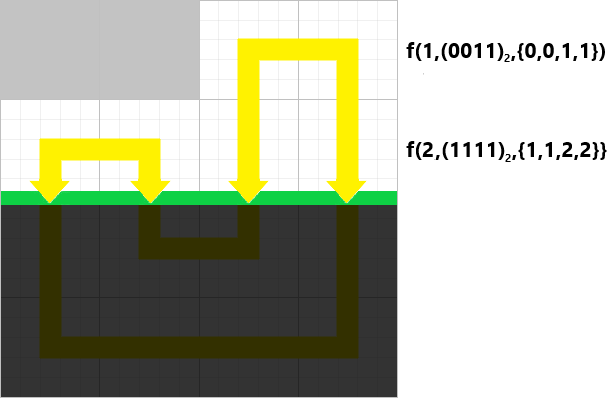
枚举完第
逐格递推 然后关键其实是逐格递推。
为了表述方便,设当前转移
那么每次转移相当于轮廓线上插头
如果你没有听懂这个关于修改的事,没有关系,这个时候就要开始分类讨论了,分类讨论的时候你应该就能听懂了。
第一种情况 新建一个连通分量,也就是我们之前说的这个:
那么这个的情况下,
即:
计算新的状态的时间为
在转移这一格之前,轮廓线应该是:
然后我们转移:
这个时候轮廓线就是:
轮廓线第二个和第三个状态被改变了。
第二种情况 接下来是合并两个连通分量,也就是我们说的:
这种情况下
接着根据
第一种情况,要连接的两个是左括号。
原本是这样的:
现在变成了这样:
就是把左边这俩连起来,那么轮廓线就进化了,这个的话用栈来维护就好。
那么需要将
时间复杂度是还算不错的
第二种情况,要连接的是两个右括号。
直接放图了,大家肯定都看的懂,看不懂我也没有办法:
把右边这俩连起来就能把那俩扭曲的右括号变成俩不扭曲的井号。
那么需要将
时间复杂度是还算**的
第三种情况,接上了对应的左括号和右括号。
那么显然这种情况只能出现在最后的时候,不然就会出现回路错误。
能把这最右边的这俩括号变成井号。
那么
时间复杂度是非常不错的
第四种情况,接上不对应的左括号和右括号。
这种就没有关系哩!来看图~
能把中间这俩背靠背的括号变成井号。
那么连结起来后
时间复杂度为非常**的
第三种情况 你可能以为是总共有六个,但是其实只有三个。
所以是事倍功半。
啊不对是事半功倍。
啊呀随便吧。
你以为我会说三句废话。
其实只要断一断。
就可以说——(啪)。
其实这里是剩下的四个插头,因为它们都是保持原来的连通分量,即
那么无论
计算新的状态的时间复杂度为
比如这个情况:
然后这个应该是这样的括号序列:
那你总不可能这么填吧:
那这个又是这样的括号序列了:
小型总结水晶 括号表示法和最小表示法是差不多的,但是除了第三种情况,每一次转移都要
逐行递推的每一个转移的状态总数为指数级,而逐格递推是
每次计算新的状态的时间两者最坏情况都是
哈希表的食用 诶是不是以为自己翻错博客了。
这么多状态,其实很多状态是无效重复的,所以可以建立一个哈希表进行记忆化,采用记忆化宽度优先搜索。
状态为
其实呢,每次判断状态
类似地,在不需要记录路径的情况下,也可以使用滚动的扩展队列来代替一个大的扩展队列。
代码 咕咕咕,现在我的模板题只能拿二十分……等我再调一调(估计到暑假前是调不出来了)。
但是下面是参考代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 #include <bits/stdc++.h> using namespace std ;const int N = 14 ;const int mod = 4001 ;int n, m, endx, endy;int now, last;long long ans;bool a[N][N];int head[mod + 5 ], nxt[2 << 24 ], que[2 ][2 << 24 ], cnt[2 ], inc[N];long long val[2 ][2 << 24 ];char s[101 ];inline void init () scanf ("%d %d" , &n, &m); for (int i = 1 ; i <= n; i ++) { scanf ("%s" , s + 1 ); for (int j = 1 ; j <= m; j ++) if (s[j] == '.' ) { a[i][j] = 1 ; endx = i; endy = j; } } inc[0 ] = 1 ; for (int i = 1 ; i <= 13 ; i ++) inc[i] = inc[i - 1 ] << 2 ; } inline void insert (int bit, long long num) int u = bit % mod + 1 ; for (int i = head[u]; i; i = nxt[i]) if (que[now][i] == bit) { val[now][i] += num; return ; } nxt[++ cnt[now]] = head[u]; head[u] = cnt[now]; que[now][cnt[now]] = bit; val[now][cnt[now]] = num; } inline void work () cnt[now] = 1 ; val[now][1 ] = 1 ; que[now][1 ] = 0 ; for (int i = 1 ; i <= n; i ++) { for (int j = 1 ; j <= cnt[now]; j ++) que[now][j] <<= 2 ; for (int j = 1 ; j <= m; j ++) { memset (head, 0 , sizeof (head)); last = now; now ^= 1 ; cnt[now] = 0 ; for (int k = 1 ; k <= cnt[last]; k ++) { long long bit = que[last][k], num = val[last][k]; int p = (bit >> ((j - 1 ) * 2 )) % 4 , q = (bit >> (j * 2 )) % 4 ; if (!a[i][j]) if (!p && !q) insert (bit, num); else if (!p && !q) if (a[i + 1 ][j] && a[i][j + 1 ]) insert (bit + inc[j - 1 ] + (inc[j] << 1 ), num); else if (!p && q) { if (a[i][j + 1 ]) insert (bit, num); if (a[i + 1 ][j]) insert (bit - inc[j] * q + inc[j - 1 ] * q, num); } else if (p && !q) { if (a[i + 1 ][j]) insert (bit, num); if (a[i][j + 1 ]) insert (bit - inc[j - 1 ] * p + inc[j] * p, num); } else if (p == 1 && q == 1 ) { int k1 = 1 ; for (int l = j + 1 ; l <= m; l ++) { if ((bit >> (l * 2 )) % 4 == 1 ) k1 ++; if ((bit >> (l * 2 )) % 4 == 2 ) k1 --; if (!k1) { insert (bit - inc[j] - inc[j - 1 ] - inc[l], num); break ; } } } else if (p == 2 && q == 2 ) { int k1 = 1 ; for (int l = j - 2 ; l >= 0 ; l --) { if ((bit >> (l * 2 )) % 4 == 1 ) k1 --; if ((bit >> (l * 2 )) % 4 == 2 ) k1 ++; if (!k1) { insert (bit - (inc[j] << 1 ) - (inc[j - 1 ] << 1 ) + inc[l], num); break ; } } } else if (p == 2 && q == 1 ) insert (bit - (inc[j - 1 ] << 1 ) - inc[j], num); else if (i == endx && j == endy) ans += num; } } } } int main () init (); work (); printf ("%lld" , ans); }
动态规划优化 单调队列优化 这是最简单的动态……优化!
就是用单调队列来优化
制造站
基建里有
相邻制造站里的干员是互相熟悉的,如果博士安排超过连续
那我们可以设计状态,对于这种一排的元素,可以设计对于每个元素选或不选,所以设
然后为了方便可以预处理出一个前缀和
发现
代码给出:
1 2 3 4 5 6 7 8 9 10 11 12 int l = 1 , r = 1 ;for (int i = 1 ; i <= n; i ++){ f[i][0 ] = max (f[i - 1 ][0 ], f[i - 1 ][1 ]); while (q[l] < i - k && l <= r) l ++; f[i][1 ] = f[q[l]][0 ] - sum[q[l]] + sum[i]; while (f[i][0 ] - sum[i] > f[q[r]][0 ] - sum[q[r]] && l <= r) r --; q[++ r] = i; } printf ("%d" , max (f[n][0 ], f[n][1 ]));
主要还是为了方便。
决策单调性优化 这是最简单的动态规划劣化。
决策单调性是在最优化 中的可能出现的一种性质,利用它我们可以降低转移的复杂度。
对于形如
要做的就是为每个决策点分配对应的决策区间。
四边形不等式 四边形不等式的定义是:
如果对于:
存在:
则
对于一个区间值关系,如果它满足交叉小于包含,就说明它满足四边形不等式 。
有一说一,上面那个东西也叫蒙日阵 ,这个东西我们之后会提到。
但是只能用在最小值上,结论如下(别问我我也不知道):
在查找最优分割点的时候,我们浪费了大量时间,那么我们可以把最优分割点保存下来,在查找的时候利用保存的最优分割点来优化查找过程,模板代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 for (int i = 1 ; i <= n; i ++) { sum[i] = sum[i - 1 ] + w[i]; sum[i + n] = sum[i + n - 1 ] + w[i]; relation[i][i] = i; relation[i + n][i + n] = i; f[i][i] = 0 ; f[i + n][i + n] = 0 ; } for (int i = 1 ; i <= n; i ++) { for (int j = 1 ; i + j <= 2 * n; j ++) { int end = i + j - 1 ; for (int k = relation[j][end - 1 ]; k < relation[j + 1 ][end]; k ++) { if (f[j][end] > dp[j][k] + f[k + 1 ][end] + sum[end] - sum[j - 1 ]) { f[j][end] = dp[j][k] + dp[k + 1 ][end] + sum[end] - sum[j - 1 ]; relation[j][end] = k; } } } }
二分栈 给出一道老生常谈的题目:
玩具装箱
为了方便整理,
制作容器的费用与容器的长度有关,根据教授研究,如果容器长度为
首先其实状态是很好设的,可以设
此处我们要证明这是一个可以用单调决策性的题目,我们就要看看这个东西七搞八搞以后能不能符合四边形不等式,考场上就代几个数字进去看看就好了,只要你不是那种运气特别差的基本都能证出来,不多说,我们开证:
先设
为了方便,我们设
最终可以化出这么个东西:
是不是似曾相识。
然后我们可以用一个栈维护每个决策的起始和结束位置。对于每个已经计算出的
在栈顶的决策起始位置判断起始位置来判决策
给出代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <bits/stdc++.h> #define int long long using namespace std ;const int N = 5e4 + 5 ;int n, L, c[N], top, sum[N], f[N];struct Htucp { int l, r, x; Htucp () {} Htucp (int _l, int _r, int _x) : l (_l), r (_r), x (_x) {} } stk[N]; inline int w (int i, int j) int res = sum[j] - sum[i] - L; res += j - i - 1 ; return res * res; } inline int find (int i) int l = stk[top].l, r = stk[top].r, mid; while (l <= r) { mid = l + r >> 1 ; if (f[i] + w (i, mid) < f[stk[top].x] + w (stk[top].x, mid)) r = mid - 1 ; else l = mid + 1 ; } return l; } signed main () int cur = 1 ; scanf ("%lld %lld" , &n, &L); for (int i = 1 ; i <= n; i ++) { scanf ("%lld" , &c[i]); sum[i] = sum[i - 1 ] + c[i]; } stk[top = 1 ] = Htucp (1 , n, 0 ); for (int i = 1 ; i <= n; i ++) { f[i] = f[stk[cur].x] + w (stk[cur].x, i); while (i < stk[top].l && f[i] + w (i, stk[top].l) < f[stk[top].x] + w (stk[top].x, stk[top].l)) top --; int u = find (i); stk[top].r = u - 1 ; if (u <= n) stk[++ top] = Htucp (u, n, i); if (i == stk[cur].r) cur ++; } printf ("%lld" , f[n]); return 0 ; }
当然我不会告诉你这题可以用斜率优化写。
时间复杂度是我们可以优化的
SMAWK 首次提出完全单调矩阵的线性求解行最小算法的是五位学者是
但是
Reduce 当求解最小值的矩阵的行数少而列数多的时,有很多列冗余,删除它们对答案没有影响,故考虑这个子过程——
至于冗余位置,当一个位置不可能是当前行的最小值位置 ,那么称为冗余位置 。
初始定义
若
若
若
我们目前维护的矩阵
若
若
给出这个过程的代码(使用链表,等等我好像不会链表):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 inline void del (int x) if (pre[x] != -1 ) suf[pre[x]] = suf[x]; else P = suf[x]; pre[suf[x]] = pre[x]; } vector <int > Reduce (vector <int > X, vector <int > Y){ for (int i = 0 ; i < Y.size (); i ++) { pre[i] = i - 1 ; suf[i] = i + 1 ; } int x = 0 , y = 0 ; for (int i = Y.size () - X.size (); i > 0 ; i --) { if (mp[X[x]][Y[y]] > mp[X[x]][Y[suf[y]]]) { y = suf[y]; del (pre[y]); if (x) { y = pre[x]; x --; } } else { if (x == X.size () - 1 ) del (suf[y]); else { y = suf[y]; x ++; } } } vector <int > ret; vector (int i = P; i != Y.size (); i = suf[i]) ret.push_back (Y[i]); return ret; }
这个过程会删除
直接暴力实现矩阵的任意列删除复杂度是不能接受的,因此实现时可以用链表维护未被删除的列的编号,这样可以
主体 这是一个递归算法,借用
若
由于有了相邻两行的限制,最后一步复杂度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void MSAWK (int vector <int > X, vector <int > Y) Y = reduce (X, Y); if (X.size () == 1 ) { M[X[0 ]] = Y[0 ]; return ; } vector <int > Z; for (int i = 0 ; i < X.size (); i ++) if (i % 2 == 0 ) Z.push_back (X[i]); MSAWK (Z, Y); for (int i = 0 ; i < X.size (); i ++) { if (i % 2 == 0 ) continue ; int l = lower_bound (Y.begin (), Y.end (), M[X[i - 1 ]]) - Y.begin (); int r = 0 ; if (i == X.size () - 1 ) r = Y.size () - 1 ; else r = lower_bound (Y.begin (), Y.end (), M[X[i + 1 ]]) - Y.begin (); M[X[i]] = Y[l]; while (l < r) { l ++; if (mp[X[i]][Y[l]] < mp[X[i], M[X[i]]]) M[X[i]] = Y[l]; } } }
矩阵优化 这是最简单的矩阵规划问题。
线性常系数递推方程 这里需要知道的是矩阵乘法,设
这里比较经典就是有关斐波那契数的题目,都很基础:
斐波那契数列
大家都知道,斐波那契数列是满足如下性质的一个数列:
现在请求出
很简单,递推,小朋友都会。
但是时间会如同不断膨胀的气球,最后,砰。所以考虑矩阵加速递推,也就是推出一个用于两个答案中间转移的矩阵
要使
因为
综上所述,
给出核心的代码:
1 2 3 4 5 6 7 8 9 10 11 12 struct Matrix { int a[3 ][3 ]; Matrix () { memset (a, 0 , sizeof a); } Matrix operator * (const Matrix &b) const { Matrix res; for (int i = 1 ; i <= 2 ; i ++) for (int j = 1 ; j <= 2 ; j ++) for (int k = 1 ; k <= 2 ; k ++) res.a[i][j] = (res.a[i][j] + a[i][k] * b.a[k][j]) % mod; return res; } } ans, base;
碰到这类题目主要是推算一个稀里糊涂的矩阵。
一些题目 这是最简单的动态规划问题……不对这好像是一堆乱七八糟的问题。
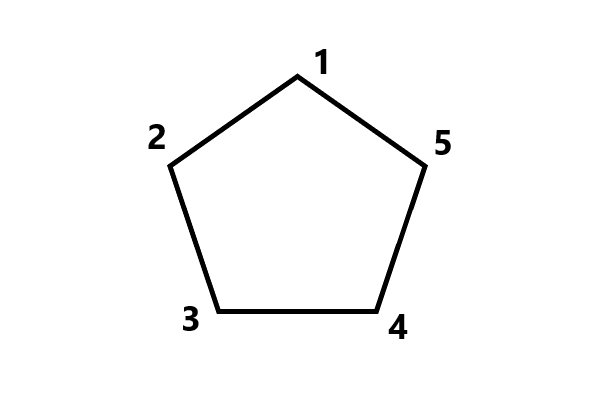
切割
煌正在教伊芙利特数学,今天讲到关于切割多边形的问题,煌为了让她明白,于是举了一个例子。
伊芙利特有一块形为
因为切法数目可能很多,只要求算出切法总数模
既然我们讲的是动态规划,所以我们用的就是动态规划(像废话)。
因为题目里比较清楚的几个状态是多边形的边数 ,切割成的份数 ,所以我们借此设状态
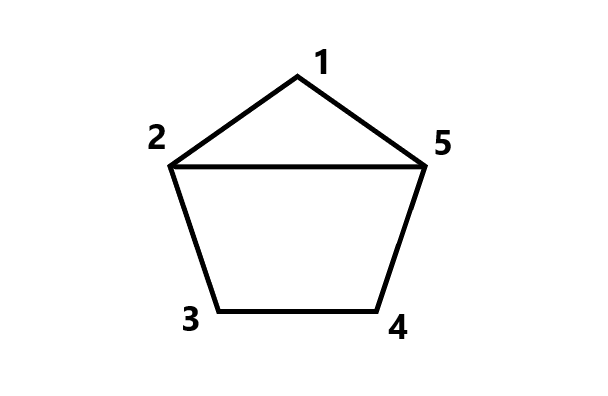
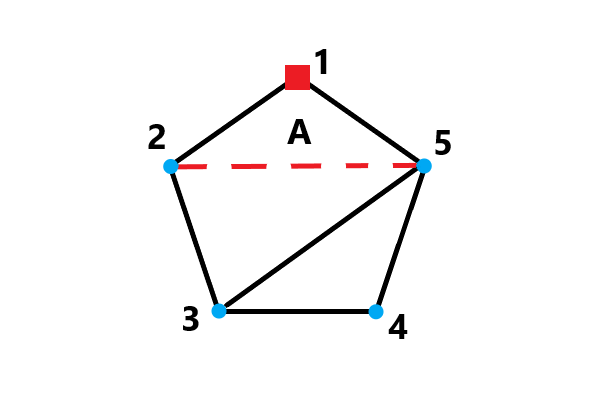
比如现在有一个五边形,我们要将其分成三份,我们先给它标号:
那么我们考虑
也就是将其分成一个三角形和一个四边形,这里的方程就是
还有一种比较难理解:
至于
然后考虑有切线穿过了
然后我们枚举这
核心代码给出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if (k > n - 2 ) return printf ("0" ) & 1 ; for (int i = 1 ; i <= n; i ++) f[i][1 ] = 1 ; for (int i = 4 ; i <= n; i ++) for (int j = 2 ; j <= min (i - 2 , k); j ++) { f[i][j] = (f[i - 1 ][j] + f[i - 1 ][j - 1 ]) % p; for (int u = 3 ; u <= i - 1 ; u ++) { int g = i - u + 2 ; for (int l = 1 ; l <= min (u - 2 , j - 1 ); l ++) f[i][j] = (f[i][j] + (f[u - 1 ][l] + f[u - 1 ][l - 1 ]) * f[g][j - l] % p) % p; } } printf ("%d" , f[n][k]);
第一次用这个切割线,发现有许多特性,你甚至可以让这个剪刀和光标一起动,还可以让它很鬼畜地在原地抖抖抖抖抖抖抖抖抖抖。
大爹点兵
博卓卡斯替和霜星在巡视乌萨斯游击队。
爱国者将自己的每一个游击队步兵分为零一二级,共三种等级,爱国者想让游击队的步兵排成一长条,仅当一些情况下,他认为这样的队伍是整齐的:
1、这个队伍的所有前缀都是整齐的。
2、这个队伍中二级兵出现的个数不少于一级兵出现的个数。
3、这个队伍中一级兵出现的个数不少于零级兵出现的个数。
请你求出有多少个长度为
一眼就是构造题(好像也不算但是真的好像啊所以就当它是构造题吧),总之就是给一些可行排列然后算方案数的。
模拟赛的时候我还自信地在头文件下写了一行注释:
/ 显然数位 /
好,事实证明,使用普通
所以我们的状态就设出来了,一个是当前兵数
关键是空间复杂度,出题人比较毒瘤,开了
但是其实发现,第一可以使用滚动数组;第二,每个兵种不都一定是
所以最后经过深思熟虑后的状态是
这个
考虑四种情况。
第一种情况,当一级兵的个数比二级兵的个数多(至于为什么这边不考虑零级兵是因为零级兵的循环范围比一级兵还小),这个时候直接跳过。
第二种情况,二级兵的个数比一级兵的个数多,我们上面也说了所以可以不用考虑零级兵,放一级兵或者零级兵:
第三种情况,当前一级兵比零级兵多,放零级兵:
第四种情况,这个时候就是放二级兵了:
最后一个竟和没写没啥区别。
目前可公开的核心代码(突然想起这个梗了,之前周六留下来准备去吃晚饭的时候听到了,现在想起来了):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for (int i = 1 ; i <= n; i ++) for (int j = 0 ; j <= i; j ++) for (int k = 0 ; k <= j; k ++) { if (j >= i - j - k) break ; else if (j <= i - j - k) f[j][k][i & 1 ] = ((j ? f[j - 1 ][k][(i - 1 ) & 1 ] : 0 ) + (k ? f[j][k - 1 ][(i - 1 ) & 1 ] : 0 ) + f[j][k][(i - 1 ) & 1 ]) % mod; else if (k <= j - 1 ) f[j][k][i & 1 ] = ((k ? f[j][k - 1 ][(i - 1 ) & 1 ] : 0 ) + f[j][k][(i - 1 ) & 1 ]) % mod; else if (i - j - k > 0 ) f[j][k][i & 1 ] = f[j][k][(i - 1 ) & 1 ] % mod; } for (int i = 0 ; i <= n; i ++) for (int j = 0 ; j <= i; j ++) if (i <= n - i - j && j <= i) ans = (ans + f[i][j][n & 1 ]) % mod;
我还是用这个切割线吧,好像不能手造切割线……然后接下来给大家看一道和上面这道很像但不是构造题的题。
源石装箱员
兔子谷矿区是泰拉大陆一个不秘密开采源石的地方,由于开采源石的难度非常高,所以开采出的会有三种纯度不同的源石矿物,分别是
由于装箱是很累的事情,所以暴行希望能以最少的装箱次数来完成她的任务,如果你不告诉她这个答案,她就会把拖把抡你脸上。
啊……这个题的状态,因为我说和前面那题是差不多的所以大家知道了吧……而且这题的范围特小,
对于这题,决策就是要不要把手里源石丢到箱子里去,所以状态很简单,用
对于丢源石,因为是将同一种丢完,所以一维状态在那个时候甚至会归零:
然后记得特判一下三种源石数量超过十个的情况,代码直接给出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 for (int i = 1 ; i <= n; i ++){ for (int j = 0 ; j <= 10 ; j ++) { for (int k = 0 ; k <= 10 ; k ++) { for (int l = 0 ; l <= 10 ; l ++) { if (j + k + l > 10 ) continue ; if (a[i] == 'A' && j) f[i][j][k][l] = f[i - 1 ][j - 1 ][k][l]; if (a[i] == 'B' && k) f[i][j][k][l] = f[i - 1 ][j][k - 1 ][l]; if (a[i] == 'C' && l) f[i][j][k][l] = f[i - 1 ][j][k][l - 1 ]; f[i][0 ][k][l] = min (f[i][0 ][k][l], f[i][j][k][l]); f[i][j][0 ][l] = min (f[i][j][0 ][l], f[i][j][k][l]); f[i][j][k][0 ] = min (f[i][j][k][0 ], f[i][j][k][l]); } } } } printf ("%d" , f[n][0 ][0 ][0 ]);
接下来来讲一道转移上很妙的题目,看懂了会非常简单(真的)。
盟友下棋
今天晚上,银灰和博士在宿舍里下中国象棋。
在
不会有人不知道炮的攻击方法吧……不知道百度,因为答案可能很大,所以只需要输出答案模
如果你不告诉他答案,他就不会当你的盟友。
棋盘大小是
然后这个数据我们选择
考虑到合法状态,每一行和每一列炮的数量必定小于三,所以用数组记有几列放了一个炮,有几列放了两个炮,这样记是因为不用记录棋盘的完整状态,那个没用。
设状态
然后分类讨论就可以了。
不放棋子 ,直接继承前一行的状态:
1 f[i][j][k] = f[i - 1 ][j][k];
这一行只放一个棋子 ,然后我们肯定不会在已经有两个棋子的那些列放,因此存在两种情况。
放在有一个棋子的列 :
因为这原来一个棋子的这一列变成了两个棋子的,所以
1 2 if (k >= 1 ) f[i][j][k] += f[i - 1 ][j + 1 ][k - 1 ] * (j + 1 );
放在没有棋子的列 :
因为原来没有棋子的列变成了有一颗棋子的列,所以
1 2 if (j >= 1 ) f[i][j][k] += f[i - 1 ][j - 1 ][k] * (m - j - k + 1 );
这一行放两颗棋子 ,然后我们和上面一样,不会把棋子放在已有两个棋子的列,因此存在三种情况:
一个放在有一颗棋子的列,另一个放在没有棋子的列 :
那么有原来有一颗棋子的那列变成两颗棋子,原来没有棋子的列变成一颗棋子,现在一颗棋子的列不增不减,反而是两个棋子的那一列,所以
1 2 if (k >= 1 ) f[i][j][k] += f[i - 1 ][j][k - 1 ] * j * (m - j - k + 1 );
都放在没有棋子的列 :
显然一个棋子的列加两个,然后这两个棋子选择放在原本没有棋子的列中,那一共是
1 2 if (j >= 2 ) f[i][j][k] += f[i - 1 ][j - 2 ][k] * C (m - j - k + 2 );
都放在有一个棋子的列 :
原本一个棋子的列少两个,两个棋子的列现在加两个,然后在一个棋子的列共
1 2 if (k >= 2 ) f[i][j][k] += f[i - 1 ][j + 2 ][k - 2 ] * ((j + 2 ) * (j + 1 ) / 2 );
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <bits/stdc++.h> #define int long long using namespace std ;const int mod = 9999973 ;const int N = 101 ;int n, m, ans;int f[N][N][N];inline int C (int x) return (x * (x - 1 ) / 2 ) % mod; } signed main () scanf ("%lld %lld" , &n, &m); f[0 ][0 ][0 ] = 1 ; for (int i = 1 ; i <= n; i ++) { for (int j = 0 ; j <= m; j ++) { for (int k = 0 ; k <= m - j; k ++) { f[i][j][k] = f[i - 1 ][j][k]; if (k >= 1 ) f[i][j][k] += f[i - 1 ][j + 1 ][k - 1 ] * (j + 1 ); if (j >= 1 ) f[i][j][k] += f[i - 1 ][j - 1 ][k] * (m - j - k + 1 ); if (k >= 2 ) f[i][j][k] += f[i - 1 ][j + 2 ][k - 2 ] * ((j + 2 ) * (j + 1 ) / 2 ); if (k >= 1 ) f[i][j][k] += f[i - 1 ][j][k - 1 ] * j * (m - j - k + 1 ); if (j >= 2 ) f[i][j][k] += f[i - 1 ][j - 2 ][k] * C (m - j - k + 2 ); f[i][j][k] %= mod; } } } for (int i = 0 ; i <= m; i ++) for (int j = 0 ; j <= m; j ++) ans = (ans + f[n][i][j]) % mod; printf ("%lld" , (ans % mod + mod) % mod); return 0 ; }
啊又是一道非常有意思的题目。
消失的小饼干
真理刚烤完了
要用剩下的
显然有很多方法,但是真理只需要你告诉她模
*本品牌仅服务于泰拉地区,与现实生活中的权威公司无关。
嗯……是一道看得出的背包问题,它出现在了模拟赛里。
但是!我看过了!所以我看到时候的时候先是惊喜了一下。
然后就悲伤了,因为我当时没有做,所以现在记录下来。
总之就是去掉一个东西然后再让你跑
嗯……
少了某件物品也就是少了一次这样的转移,直接来看代码啦:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <bits/stdc++.h> #define int long long using namespace std ;const int mod = 1e9 + 7 ;const int N = 1e4 + 1 ; int n, m;int w[N], f[N], g[N];signed main () scanf ("%lld %lld" , &n, &m); for (int i = 1 ; i <= n; i ++) scanf ("%lld" , &w[i]); f[0 ] = 1 ; for (int i = 1 ; i <= n; i ++) for (int j = m; j >= w[i]; j --) f[j] = (f[j] + f[j - w[i]]) % mod; for (int i = 1 ; i <= n; i ++) { memset (g, 0 , sizeof (g)); g[0 ] = 1 ; for (int j = 1 ; j <= m; j ++) { if (w[i] > j) g[j] = f[j] % mod; else g[j] = (f[j] - g[j - w[i]] + mod) % mod; } printf ("%lld\n" , g[m]); } return 0 ; }
当然也可以先跑一遍然后再跑一遍,等于是还原操作:
1 2 3 4 5 6 7 8 for (int i = 1 ; i <= n; i ++){ for (int j = w[i]; j <= m; j ++) f[j] = (f[j] - f[j - w[i]] + mod) % mod; printf ("%lld\n" , f[m]); for (int j = m; j >= v[i]; j --) f[j] = (f[j] + f[j - w[i]]) % mod; }
来给出一道以前模拟赛的题,但是当时因为水平太烂没有做出来。
三……嘭!
1、用源石技艺做出一个炸药或者销毁一个炸药,代价为
2、用精妙的源石技艺将已经做出来的炸药复制一份,代价为
值得一提的是,
现在她想让你告诉她做
其实这次做到了也没有做出来,果然还是太烂了。
但是其实是一个简单推方程的题目,首先设计状态
然后你就去考虑分类讨论。
如果当前 ,肯定只能从
如果在使用减操作,
但是如果直接从
所以当
所以这个方程是:
如果当前 ,
但是
基本代码如下:
1 2 3 4 5 6 7 8 9 f[1 ] = x; for (int i = 2 ; i <= n; i ++){ f[i] = f[i - 1 ] + x; if (i & 1 ) f[i] = min (f[i], f[(i + 1 ) / 2 ] + x + y); else f[i] = min (f[i], f[i / 2 ] + y); }
然后来讲一道必讲的题目,呃好吧其实我也不是觉得必讲,但是真的很有意思……
宿舍今天的健康餐
芙蓉是一个擅长做菜的医疗干员,她共掌握 烹饪方法 ,且会使用 主要食材 做菜。为了方便叙述,我们对烹饪方法从
芙蓉做的每一道菜都将使用恰好一种 烹饪方法与恰好一种 主要食材。更具体地,芙蓉会做
芙蓉今天要准备一桌菜招待博士和炎熔,然而三个人对菜的搭配有不同的要求,更具体的,对于一种包含
1、芙蓉不会让大家饿肚子,所以将做至少一道菜 ,即
2、炎熔希望品尝不同烹饪方法做出的菜,因此她要求每道菜的烹饪方法互不相同 。
3、博士不希望品尝太多同一食材做出来的菜,因此他要求每种主要食材 至多在一半 的菜(即
这些要求难不倒芙蓉,但她想知道共有多少种不同的符合要求的搭配方案。两种方案不同,当且仅当存在至少一道菜在一种方案中出现,而不在另一种方案中出现。
身为博士的你只需要告诉芙蓉所有要求的搭配方案数对
题意就是给一个矩阵然后求合法方案数,然后这个合法方案要注意的就是某一列里的主要食材是不能超过总共选的一半的(每一行表示了主要食材,每一列表示了烹饪方式 ),而且只会有一列不合法 ,因为不可能有两列都超过选的一半,如果还没有听懂可以考虑类似这样的一个表格:
也就是说烹饪方法只能使用一种 ,但是一道菜可以用多个主要食材 ,做多少道这样的菜也不同 。
那么看到这种算方案数的题目,我们优先想想枚举这个方案麻烦不麻烦,如果麻烦就尝试使用容斥吧。
对于这个题目,我们可以使用容斥,也就是每行选不超过一个的方案数减去每行选不超过一个,且某一列选了超过一半的方案数,然后我们来枚举那一个不合法的列。
接下来来设计状态,用
如果看不懂我们可以慢慢拆这个式子,首先可以将其分为三个部分:
这个是前面的状态,这个应该不用多说。
对于选第
对于这一行不给这一列的情况,对于这一行的和减去这一格,因为不用在意给其他什么列,反正就不是给它的,这个是没有关系的,然后至于转移和上面是一样的,其他列获得加一。
时间复杂度是
然后发现其实我们不用考虑其他行的个数,也就是我们前面考虑的
这里感觉转移的话(如果前面你好好看了),是非常好懂的!!!
这边
总方案数就是再开一个
总复杂度就会降为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <bits/stdc++.h> #define int long long using namespace std ;const int mod = 998244353 ;const int N = 101 ;const int M = 2e3 + 1 ;int n, m, a[N][M], sum[N][M], g[N][N], f[N][N * 2 ], ans;signed main () scanf ("%lld %lld" , &n, &m); for (int i = 1 ; i <= n; i ++) for (int j = 1 ; j <= m; j ++) { scanf ("%lld" , &a[i][j]); sum[i][0 ] = (sum[i][0 ] + a[i][j]) % mod; } for (int i = 1 ; i <= n; i ++) for (int j = 1 ; j <= m; j ++) sum[i][j] = (sum[i][0 ] - a[i][j] + mod) % mod; for (int col = 1 ; col <= m; col ++) { memset (f, 0 , sizeof f); f[0 ][n] = 1 ; for (int i = 1 ; i <= n; i ++) for (int j = n - i; j <= n + i; j ++) f[i][j] = (f[i - 1 ][j] + f[i - 1 ][j - 1 ] * a[i][col] % mod + f[i - 1 ][j + 1 ] * sum[i][col] % mod) % mod; for (int i = 1 ; i <= n; i ++) ans = (ans + f[n][n + i]) % mod; } g[0 ][0 ] = 1 ; for (int i = 1 ; i <= n; i ++) for (int j = 0 ; j <= n; j ++) g[i][j] = (g[i - 1 ][j] + (j > 0 ? g[i - 1 ][j - 1 ] * sum[i][0 ] % mod : 0 )) % mod; for (int i = 1 ; i <= n; i ++) ans = (ans - g[n][i] + mod) % mod; printf ("%lld" , ans * (mod - 1 ) % mod); return 0 ; }
看一下最后的取反:
至于为什么要取反,是因为我们做的是非法方案减去全部方案,所以取个反就行了。
接下来记录一道经典的题目。
花盆
波登可有两列花盆,她想让这两列花变得一模一样,现在她决定做三种操作:
1、移除一盆花
2、放入一盆花
3、将一盆花改为另一盆花
她不想太累,所以她想知道将第一列花改成第二列花的最小操作次数,希望你能告诉她,不然她会对你使用花香疗法。
非常经典的序列题,在这里设的状态也比较难想,
递推过去,如果第
不然就考虑三种情况。
第一种,如果能将
第二种,如果能将
第三种,如果能将
然后在其中取最小值,主要代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 for (int i = 1 ; i <= n; i ++) f[i][0 ] = i; for (int i = 1 ; i <= m; i ++) f[0 ][i] = i; for (int i = 1 ; i <= n; i ++) for (int j = 1 ; j <= m; j ++) { if (a[i] == b[i]) f[i][j] = f[i - 1 ][j - 1 ]; else f[i][j] = min (f[i - 1 ][j], min (f[i][j - 1 ], f[i - 1 ][j - 1 ])) + 1 ; }
接下来是一道使用拓扑排序的题,因为碰到了所以就随手记录一下吧(虽然说难度并不是很大)。
信仰号街车
愿光芒铺陈你的前路,愿虔诚与信念永伴你身。
空弦正在麦田中闲逛,在这片巨大的麦田里,有许多修道院,麦田中有一些单向路能够连接修道院,而且保证这些路没有环。
现在空弦希望从
如果你不告诉她答案的话,她会在舰桥上让你当她的靶子。
因为是有向无环图,所以我们可以考虑使用拓扑排序。
然后我们考虑设计状态,这个地方我们定义
因为拓扑的一个重要性质就是只有入度为
于是可以参考最短路的转移来设计方程:
输出路径的时候就在当时记录下来然后用栈全部一坨输出出来,完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 #include <bits/stdc++.h> using namespace std ;const int N = 5e3 + 1 ;int n, m, k;struct Edge { int nxt, to, dis; } edge[N << 1 ]; int head[N], cnt;int in[N], f[N][N], pre[N][N], ans;vector <int > s;stack <int > path;inline void add_edge (int u, int v, int w) edge[++ cnt] = (Edge) {head[u], v, w}; head[u] = cnt; } queue <int > Q;void toposort () for (int i = 1 ; i <= n; i ++) if (!in[i]) Q.push (i); while (!Q.empty ()) { int u = Q.front (); Q.pop (); s.push_back (u); for (int i = head[u]; i; i = edge[i].nxt) if ((-- in[edge[i].to]) == 0 ) Q.push (edge[i].to); } } int main () memset (f, 0x3f , sizeof (f)); memset (pre, -1 , sizeof (pre)); scanf ("%d %d %d" , &n, &m, &k); for (int i = 1 , u, v, w; i <= m; i ++) { scanf ("%d %d %d" , &u, &v, &w); add_edge (u, v, w); in[v] ++; } toposort (); f[1 ][1 ] = 0 ; for (int k = 0 ; k < s.size (); k ++) { int u = s[k]; for (int i = head[u]; i; i = edge[i].nxt) for (int j = 2 ; j <= n; j ++) if (f[u][j - 1 ] + edge[i].dis < f[edge[i].to][j]) { f[edge[i].to][j] = f[u][j - 1 ] + edge[i].dis; pre[edge[i].to][j] = u; } } for (int i = n; i >= 1 ; i --) if (f[n][i] <= k) { ans = i; break ; } printf ("%d\n" , ans); int pos = n, dep = ans; while (pos != -1 ) { path.push (pos); pos = pre[pos][dep]; dep --; } while (!path.empty ()) { printf ("%d " , path.top ()); path.pop (); } return 0 ; }